Classical CV Pipeline
Pipeline
-
Keypoint detector
关键点检测器,找到图像中有意义的点(角点、斑点等)。
例如 Harris corner detector。
-
Keypoint descriptor
关键点描述子,在兴趣点周围提取局部特征向量。
例如 SIFT。
-
Image representation
图像表示,把多局部特征聚合成固定长度向量(如直方图),便于分类器处理。
例如 Bag-of-Visual-Words。
-
Classifier
分类器,在聚合表示上训练浅模型完成最终分类任务。
例如 SVM, logistic regression
Keypoint detector
Where to look。传统算法多基于梯度、Hessian、角点响应等设计启发式准则。常见的方法有 Harris,DoG 等。
Descriptor
What is around that point。常见的方法有 SIFT(Scale-Invariant Feature Transform),配合 DoG 使用可以做到尺度等变性。
SIFT 的步骤:
本质上是把每个关键点映射成一个定长的特征向量,且这种映射具有鲁棒性。
- 检测出关键点。
- 为每个关键点确定主方向(orientation),通常使用圆形邻域进行 vote(注意需要按距离加权)。并做方向归一化,也即进行旋转使主方向朝向 0°。
- 旋转后,在关键点周围选取一个 16×16 的 patch,注意坐标不一定整数,需用双线性插值。
- 将该 patch 划分为 4×4 个子区域,每子区域 4×4 像素。
把 360° 分成 8 个 bins,每个子区域像素以梯度大小为权加入 bins,最后每个子区域得到一个 8 维向量。
- 合起来得到 128 维描述子,最后进行归一化、阈值截断、再归一化。其中归一化是避免整体亮度变化影响,阈值截断是避免局部阴影的影响。
Aggregation
How the whole image is。常见的方法有 Bag-of-Visual-Words。
BoVW 的步骤:
本质上是把不确定数量的局部描述子映射成固定长度的全局表示。
- 收集描述子。
- 使用聚类算法(如 k-means)把描述子聚成 K 个簇中心,称为 visual words。
- 对一张图中每个描述子找最近的 visual word,可以是硬分配(单独分配)或软分配(分配权重)。
- 统计每个词的出现次数,得到长度为 K 的全局表示向量。
注:BoVW 统计词频,不记录词出现的相对位置,故会丢失空间信息。比如鼻子长在眼睛上,BoVW 并不能发现差异。
Classifier
Decision for the task。常用浅学习模型,如 logistic regression(二分类)、SVM、小型神经网络等。
本质上是把聚合好的向量映射到类别概率或类别标签。
注:这些分类器只看聚合后的全局表示,不直接访问原像素。
Problems
- 依赖人工设计的特征和启发式规则。
- 流水线会产生错误累积。
- 难以理解高层语义,比如部分(part)、种类(category)、语境(context)等。
- 难以利用海量数据进行优化
- 对某一事物的识别不易泛化到另外事物。
Learning-based CV
Advantages
传统 CV 是设计特征,学习型 CV 是从数据中学习特征。
好处:
- 端到端(end-to-end),能直接针对最终任务优化所有参数,避免手工设计中各阶段不一致的目标。
- 自动学习高层语义,从边缘到部分再到对象/场景。
- 能够随数据规模增长而提高性能。
注:学习型方法虽然在很多视觉任务中表现更好,但在数据稀缺或实时/嵌入式场景中经典方法仍有价值。
Why It Took Off
- 算法(Algorithm):深度学习架构(多层神经网络、反向传播、优化方法)与研究突破(如 ReLU、BatchNorm、ResNet 等)。
- 数据(Data):ImageNet 等大规模标注数据集让复杂模型能被充分训练。
- 计算资源(Compute):GPU、TPU 等硬件加速以及高效并行使大模型训练成为可能。当然电能也非常重要。
Machine Learning
Set Up the Task
假设我们想要实现 MNIST 二分类,也即给定一张手写数字图像,判断它是否为数字 5。
输入:x∈R784,表示 28×28 灰度图像展平的 784 维向量。
标签:y∈{0,1},是否为数字 5 的标签。
输出:
- 软分类:p(y=1∣x)∈[0,1]
- 硬分类:p(y=1∣x)≥τ,则预测为 1,否则为 0。
模型:h(x;θ),其中 θ 为待优化参数。
Prepare the Data
使用 MNIST 数据集。
预处理:
- 标准化:
- 将像素值除 255 从 [0,255] 缩放到 [0,1]。
- 或做零均值单位方差标准化 x′=σx−μ。
- 数据增强:随机平移、旋转少量角度、缩放、弹性变形等。
- 转换为模型需要的数据结构:
- 对于线性模型/MLP:展平为 (784,) 向量。
- 对于 CNN:保留形状 (1, 28, 28) 。
- 划分数据集:
- 划分为训练集、验证集和测试集。
- 按照训练方法进一步划分,比如划分出 mini-batch。
注:区分 train、validation、test、inference
| 阶段 | 核心目的 | 是否更新模型参数 | 是否需要标签 |
|---|
| 训练 (Train) | 学习规律 | Y | Y |
| 验证 (Validation) | 调超参数、选模型 | N | Y |
| 测试 (Test) | 最终评估泛化能力 | N | Y |
| 推理 (Inference) | 实际应用预测 | N | N |
Build a Model
模型负责利用给定的输入产生输出,也即给出一个函数 h(x;θ)∈[0,1],其中 θ 为待优化参数。
Logistic Regression
逻辑回归,线性模型。
令 z=θ⊤x+b 为输入的线性打分。则模型为:
h(x;θ,b)=σ(z)=1+e−z1
其中参数 θ∈R784,b∈R。
MLP Neural Network
多层感知器(MLP),非线性模型,可以处理非线性可分问题。
若干线性层(矩阵乘法)与非线性激活函数交替堆叠。
每层 h=g(Wx+b),其中 g 是激活函数。
通过施加多层非线性变换, MLP 可以把原来线性不可分的点集映射到一个新的特征空间中,使其更线性可分。
设网络共有 L 层(含输入输出层)。记:
- 输入:x∈Rn1
- 第 ℓ 层的神经元数:nℓ
- 第 ℓ 层的权重矩阵:
W(ℓ)∈Rnℓ×nℓ−1,
wij(ℓ) 元代表边 aj(ℓ)→ai(ℓ+1) 的权重
- 第 ℓ 层的偏置向量:b(ℓ)∈Rnℓ
其中 ℓ=1,2,…,L。
前向传播递推关系:
z(ℓ)=W(ℓ)a(ℓ−1)+b(ℓ),ℓ=1,2,…,L
a(ℓ)=gℓ(z(ℓ))
其中:
- a(1)=x
- a(ℓ) 为第 ℓ 层输出,第 ℓ+1 层输入,ℓ=1,2,…,L−1
- a(L) 为最终输出
- gℓ:Rnℓ→Rnℓ 是逐元素激活函数
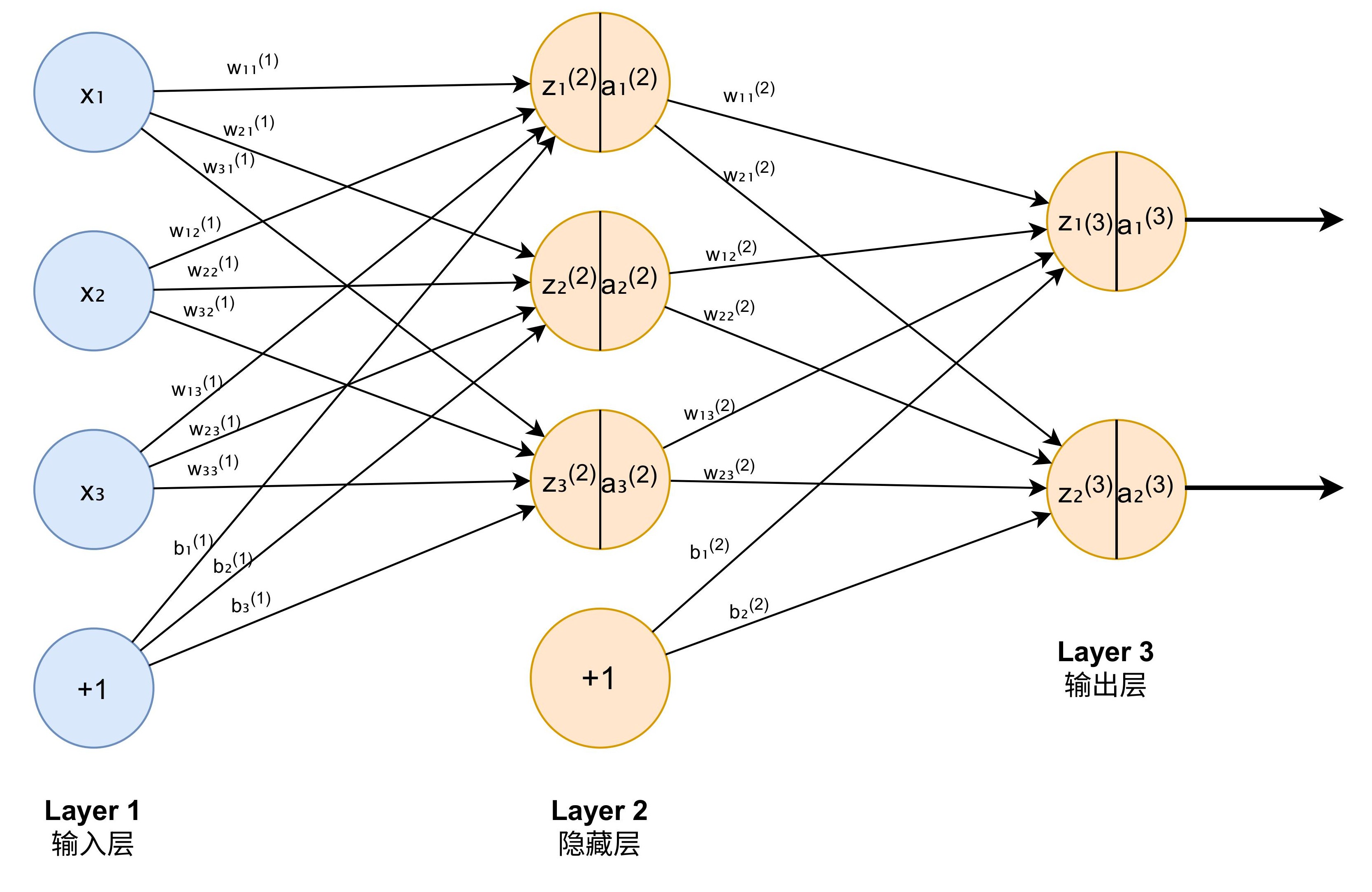 图 1:神经网络示意图,其中有竖线的橙色圆圈代表 neurons,有向边代表 params
图 1:神经网络示意图,其中有竖线的橙色圆圈代表 neurons,有向边代表 params
紧凑形式:
MLP 整体可视为一个复合函数:
h(x;Θ)=(gL∘τL∘gL−1∘τL−1∘⋯∘g1∘τ1)(x)
其中 τℓ(a)=W(ℓ)a+b(ℓ) 为仿射变换,∘ 表示函数复合。
参数集合:
Θ={W(1),b(1),W(2),b(2),…,W(L),b(L)}
激活函数:
-
Sigmoid:
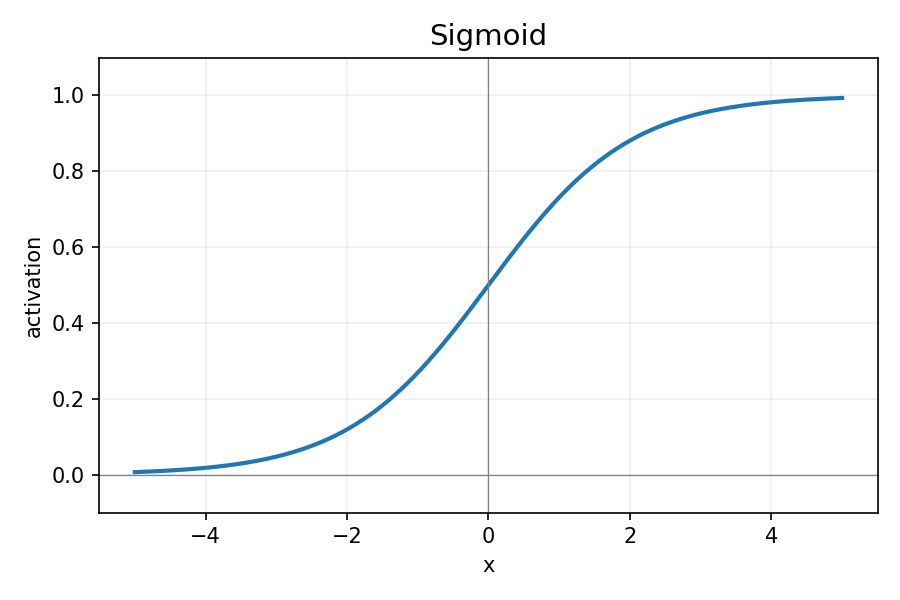 图 2:Sigmoid 函数
σ(x)=1+e−x1,σ′(x)=σ(x)(1−σ(x))
图 2:Sigmoid 函数
σ(x)=1+e−x1,σ′(x)=σ(x)(1−σ(x))
- 优点:概率化输出。
- 缺点:易饱和导致梯度消失,输出非零中心。
- 何时用:二分类输出层,隐藏层一般不推荐。
-
tanh:
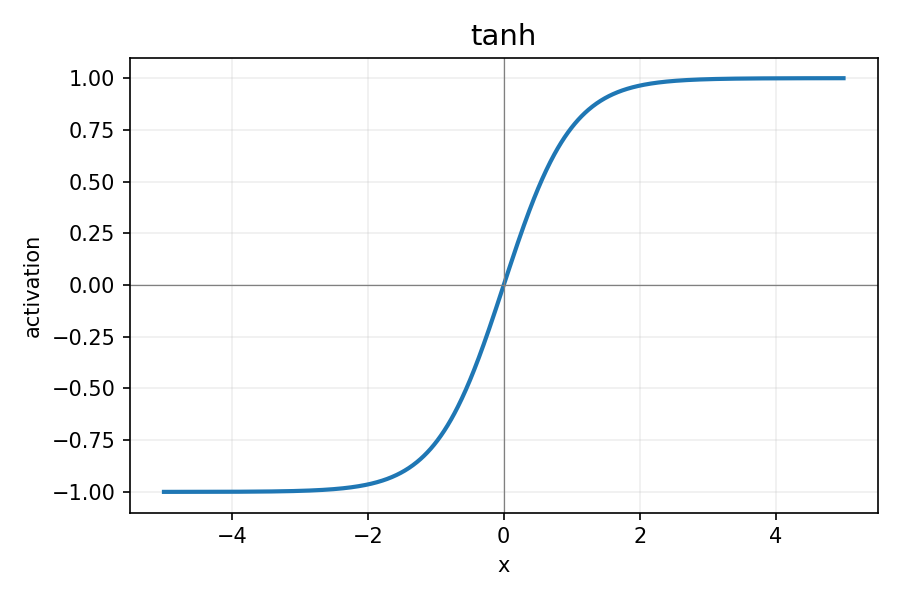 图 3:tanh 函数
tanh(x)=ex+e−xex−e−x,tanh′(x)=1−tanh2(x)
图 3:tanh 函数
tanh(x)=ex+e−xex−e−x,tanh′(x)=1−tanh2(x)
- 优点:输出以 0 为中心,训练通常比 sigmoid 稳定。
- 缺点:仍会饱和(梯度消失)。
- 何时用:历史上隐藏层曾常用,现代深层网络多用 ReLU。
-
ReLU:
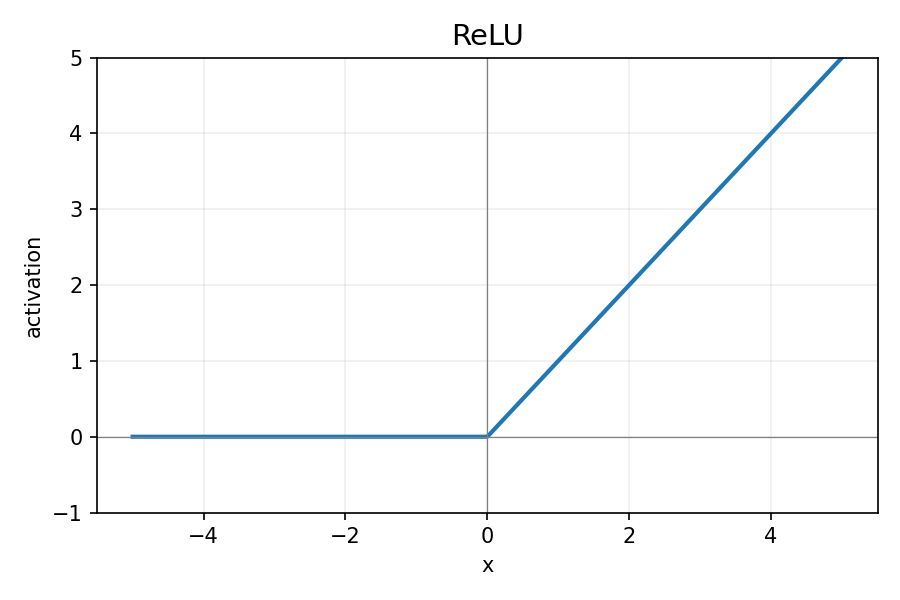 图 4:ReLU 函数
ReLU(x)=max(0,x)
图 4:ReLU 函数
ReLU(x)=max(0,x)
- 优点:计算简单、正区间梯度恒为 1,缓解梯度消失,训练快且产生稀疏激活。
- 缺点:可能出现 Dead ReLU(神经元输出恒为 0)。
- 何时用:默认隐藏层首选激活。
-
Leaky ReLU:
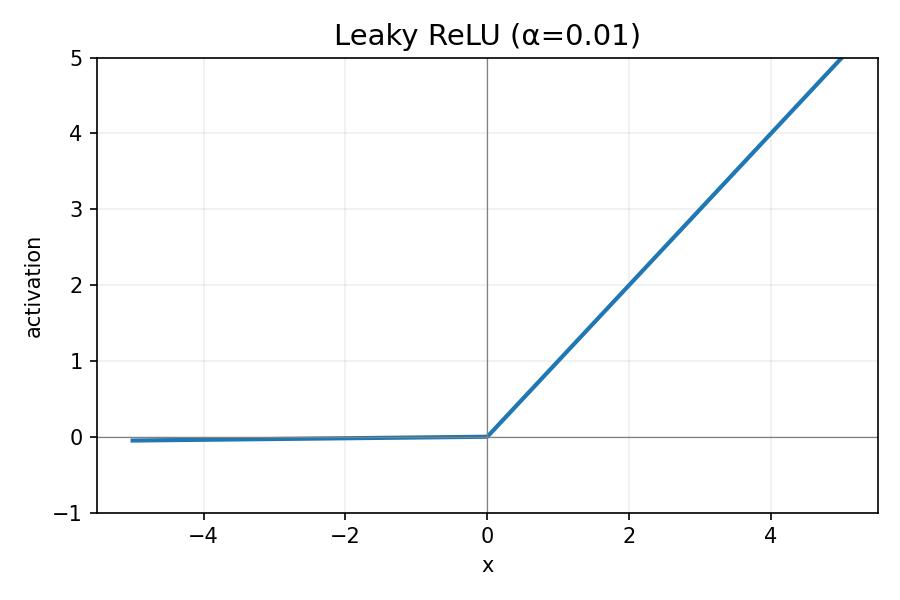 图 5:Leaky ReLU 函数
LeakyReLU(x)=max(αx,x)(usually α=0.01)
图 5:Leaky ReLU 函数
LeakyReLU(x)=max(αx,x)(usually α=0.01)
- 优点:较少死神经元,训练更稳健。
- 缺点:引入小负输出,微弱影响稀疏性。
- 何时用:遇到 Dead ReLU 或需更鲁棒时。
-
ELU:
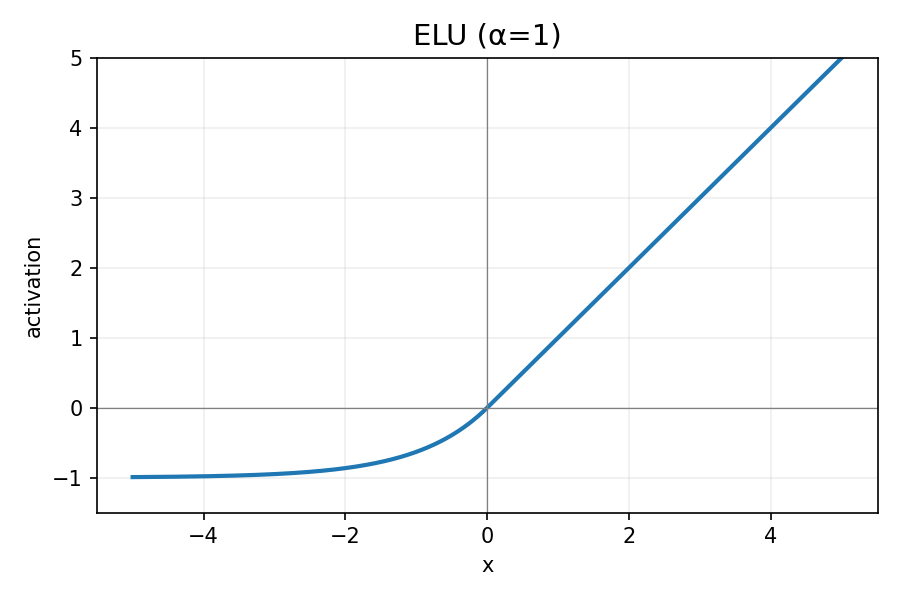 图 6:ELU 函数
ELU(x)={x,α(ex−1),x≥0,x<0
图 6:ELU 函数
ELU(x)={x,α(ex−1),x≥0,x<0
- 优点:负区间平滑、均值可接近 0,训练稳定性好。
- 缺点:含指数计算,开销比 ReLU 大。
- 何时用:重视稳定性且能接受稍高计算成本时。
-
Maxout:
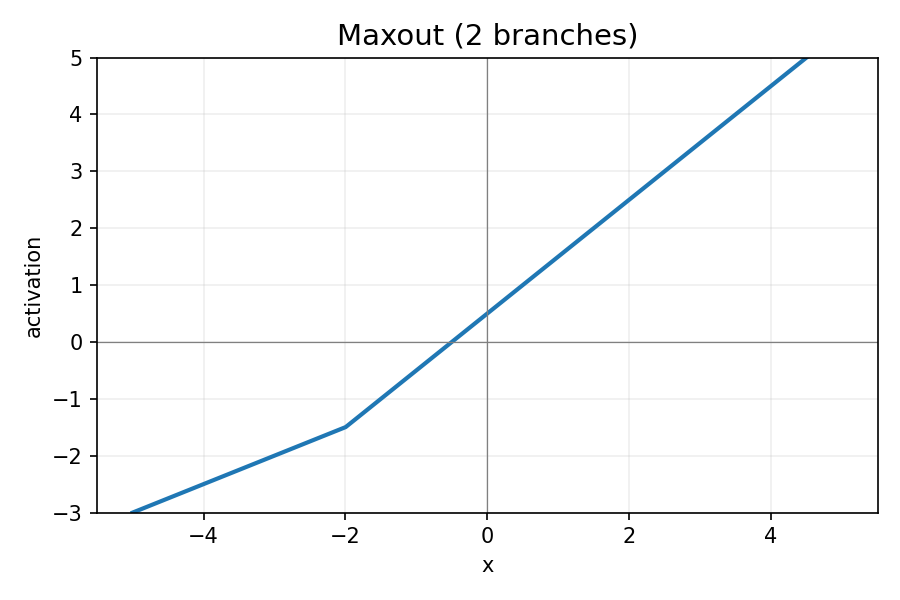 图 7:Maxout 函数
Maxout(x)=max(w1⊤x+b1,w2⊤x+b2)
图 7:Maxout 函数
Maxout(x)=max(w1⊤x+b1,w2⊤x+b2)
- 优点:分段线性拟合能力强,对 Dropout 友好。
- 缺点:参数与计算量成倍增加。
- 何时用:需要更高模型容量且资源充足时。
注:ReLU 计算简单、正区间梯度为 1,可缓解梯度消失并加速收敛,是稳健的默认选择。
Define the Loss Function
我们要给出具体的损失函数与训练目标(optimization objective)。
MLE
最大似然估计(Maximum Likelihood Estimation)。
把模型看作给定输入时产生输出标签的概率模型:
p(y=1∣x;θ)=h(x;θ),p(y=0∣x;θ)=1−h(x;θ).
假设样本独立,则对整个训练集出现的概率估计(似然函数)为:
p(Y∣X;θ)=i=1∏nh(x(i);θ)y(i)(1−h(x(i);θ))1−y(i).
其中 Y 为标签向量,X 为输入向量,y(i) 为第 i 个样本的标签,x(i) 为第 i 个样本的输入。
每个模型(参数)都可以计算出对应的训练集似然。我们应当选取一个模型(参数),使得这个模型(参数)计算出的训练集似然是在整个模型空间(参数空间)中最大的。此即最大似然估计:
θ∗=θargmaxp(Y∣X;θ)
NLL/Cross-Entropy
最大化似然等同于最小化负对数似然(Negative Log-Likelihood)。
交叉熵:
对于定义在同一个离散集合 X 上的两个概率分布 P 和 Q
H(P,Q)=−x∈X∑P(x)logQ(x)
其中 H(⋅, ⋅) 即为交叉熵函数。
NLL/CE:
针对这个二分类问题,为了使得梯度大小与样本数无关,我们取平均形式:
L(θ)=−n1logp(Y∣X;θ)=−n1i=1∑n[y(i)logh(x(i);θ)+(1−y(i))log(1−h(x(i);θ))]=n1i=1∑nH(y(i),h(i))
对单样本的损失:
ℓ(i)(θ)=−[y(i)logh(x(i);θ)+(1−y(i))log(1−h(x(i);θ))]=H(y(i),h(i))
若加入 L2 正则化:
Lreg(θ)=L(θ)+2λ∥θ∥2
其中 λ 为超参数。
注:
- NLL 使用对数,在概率极小时数值仍然稳定,且对于小概率惩罚更大。
- NLL 使用对数,将复杂乘法转化为加法。
- 多元 NLL 和多元 CE 在数学上等价,不过 NLL 属于统计学,CE 属于信息论(damn)
训练等价于最小化损失函数。我们分别推导 Logistic Regression 和 MLP 的反向传播过程。
Logistic Gradient Descent
设 Logistic Regression 模型为:
- 线性项 z=θ⊤x
- 输出 h=σ(z)=1/(1+e−z)
- 单样本损失 ℓ(θ)=−[ylogh+(1−y)log(1−h)]
链式法则求导:
- 对 h 求导:
∂h∂ℓ=−(hy−1−h1−y)
- 对 z 求导:
∂z∂h=h(1−h)
从而:
∂z∂ℓ=∂h∂ℓ∂z∂h=h−y
- 对 θ 求导:
∂θ∂ℓ=∂z∂ℓ∂θ∂z=(h−y)x
全量梯度:
∇θL(θ)=n1i=1∑n(h(x(i);θ)−y(i))x(i)=n1XT(H−Y)
注:
h(x(i);θ)−y(i) 是模型的预测误差(残差),乘以输入 x(i) 得到该样本对梯度的贡献。
误差的绝对值越大,说明在该样本上的预测越差,该样本对参数更新的影响越大,从而引导模型向减小该误差的方向调整。
MLP Backpropagation
对于多层神经网络,我们需要计算损失函数对每一层参数的梯度。反向传播算法通过链式法则高效地完成这一计算。
前向传播过程中有:
z(ℓ)a(ℓ)=W(ℓ)a(ℓ−1)+b(ℓ)=gℓ(z(ℓ))
其中 a(1)=x,a(L)=h(x;Θ) 为最终输出。
定义误差信号:
δ(ℓ)=∂z(ℓ)∂L
表示损失函数对第 ℓ 层线性输出 z(ℓ) 的梯度。
-
输出层误差:
对于二分类问题,输出层使用 Sigmoid 激活 gL(z)=σ(z),损失为二元交叉熵:
δ(L)=a(L)−y
其中 y 是标签向量。
证明:以一维为例。
δ(L)=∂z(L)∂L=∂a(L)∂L⋅∂z(L)∂a(L)=(−a(L)y+1−a(L)1−y)⋅a(L)(1−a(L))=a(L)−y
-
误差反向传播:
对于隐藏层 ℓ=L−1,L−2,…,2:
δ(ℓ)=((W(ℓ+1))⊤δ(ℓ+1))⊙gℓ′(z(ℓ))
其中 ⊙ 表示逐元素相乘,gℓ′ 为激活函数的导数。
证明:
根据链式法则,第 ℓ 层的误差信号来自第 ℓ+1 层:
δj(ℓ)=∂zj(ℓ)∂L=k=1∑nℓ+1∂zk(ℓ+1)∂L⋅∂zj(ℓ)∂zk(ℓ+1)
由于 zk(ℓ+1)=∑iwki(ℓ+1)ai(ℓ)+bk(ℓ+1) 且 ai(ℓ)=gℓ(zi(ℓ)):
∂zj(ℓ)∂zk(ℓ+1)=wkj(ℓ+1)⋅gℓ′(zj(ℓ))
代入得:
δj(ℓ)=(k∑wkj(ℓ+1)δk(ℓ+1))gℓ′(zj(ℓ))
写成矩阵形式即证。
-
权重梯度:
∂W(ℓ)∂L=δ(ℓ)(a(ℓ−1))⊤
即:
∂wij(ℓ)∂L=δi(ℓ)⋅aj(ℓ−1)
-
偏置梯度:
∂b(ℓ)∂L=δ(ℓ)
Parameter Update Methods
得到梯度后,使用优化器更新参数。
-
全量批量梯度下降(Full-batch GD):
θ′=θ−α∇θL(θ)
- 优点:稳定。
- 缺点:每步计算量大,不能很好地并行和进行实时更新。
-
随机梯度下降(Stochastic GD,SGD):
每次取一个样本更新:
θ′=θ−α(hθ(x(i))−y(i))x(i)
- 优点:更新频繁、噪声可帮助跳出鞍点。
- 缺点:噪声导致收敛震荡,不稳定。
-
小批量梯度下降(Mini-batch GD):
取 batch 为 B,size 为 B:
θ′=θ−αB1i∈B∑(hθ(x(i))−y(i))x(i)
在 GPU 上常用,平衡效率与稳定性。
-
自适应优化器(Adaptive Optimizers):
- 动量法:Momentum
- 自适应学习率:Adam、RMSProp 等
Learning Rate
学习率 α 的选择对训练很关键。
常用策略:
- 固定学习率
- 学习率衰减:
- step decay:每隔若干 epoch 乘以一个衰减因子
- exponential decay:每轮指数衰减
- 基于验证集自动调整:
监控验证集表现,若连续若干轮不提升,自动降低学习率。如 PyTorch 的
ReduceLROnPlateau
- 学习率预热:
训练初期用小学习率 warm up,逐渐增加到目标值,再衰减。
- 提前停止:
监控验证集误差,若连续若干轮不下降则停止训练,防止过拟合。
Difficulty
神经网络训练是非凸优化,常见问题:
- 鞍点(saddle points)导致局部最优解。
- 过参数化导致高维空间,其中有大量平坦区域(flat plateaus),梯度太小,移动慢;同时高维下特征值多,更容易出现鞍点(Hessian 中正负特征值同时出现)。
因此,直接基于全量批量 GD 在深度学习中往往不够鲁棒,SGD 的噪声反而有帮助。
Testing
训练完成后要在测试集上评估模型的泛化能力(generalization)。
Evaluation Metrics:
| 缩写 | 全称 | 含义 |
|---|
| TP | True Positives | 1 预测为 1 的数量 |
| FP | False Positives | 0 预测为 1 的数量 |
| FN | False Negatives | 1 预测为 0 的数量 |
| TN | True Negatives | 0 预测为 0 的数量 |
- 准确率:
Accuracy=TOTTP+TN
- 精确率:
Precision=TP+FPTP
- 召回率:
Recall=TP+FNTP
- F1-score:
2Precision+RecallPrecision⋅Recall
- 混淆矩阵(Confusion Matrix):展示 TP/FP/TN/FN 的分布
- 泛化间隙(Generalization Gap):
Generalization Gap=Etest[loss]−Etrain[loss]
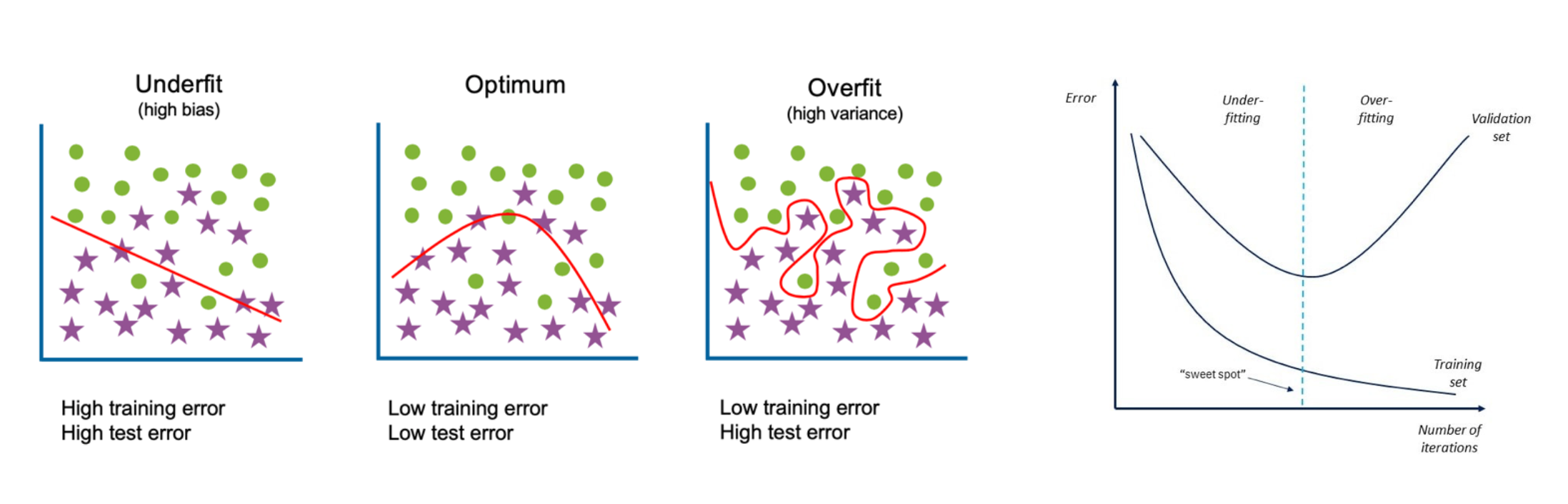 图 8:欠拟合与过拟合图示
图 8:欠拟合与过拟合图示
注:
Problems for Applying MLP to CV
需要将图像平坦化(flatten)为向量:
- 会破坏图像的局部结构,空间邻接关系在展平的向量中不再邻接。
- 参数数目随像素数线性增长,对高分辨率图像计算与内存负担大。
- 对于输入图像的微小平移操作,MLP 很难保持输出基本不变,也即很难具有平移不变性。
因此在视觉任务中更常用 Convolutional Neural Networks(CNNs),保留空间结构并通过参数共享大幅减少参数量。