问题引入
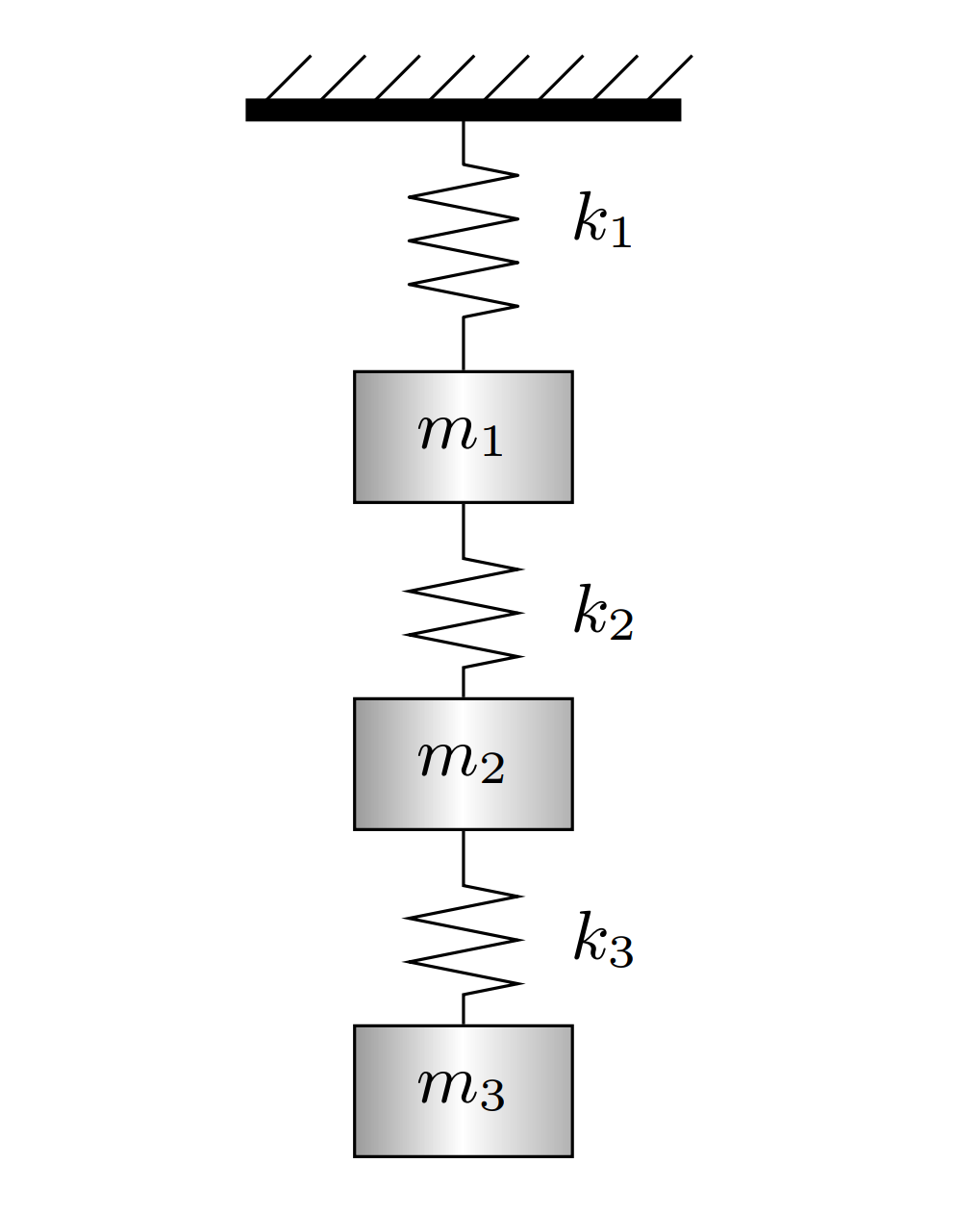
图 1:弹簧-质点系统
考虑弹簧-质点系统,质点 m j m_j m j y j ( t ) y_j(t) y j ( t )
M y ¨ + K y = 0 M\ddot{y} + Ky = 0 M y ¨ + K y = 0 其中:
M = diag ( m 1 , m 2 , m 3 ) M = \text{diag}(m_1,m_2,m_3) M = diag ( m 1 , m 2 , m 3 ) K K K
设 y j ( t ) = x j e i ω t y_j(t) = x_j e^{i\omega t} y j ( t ) = x j e iω t 谐波振动假设 ),代入得:
( − ω 2 M + K ) x = 0 ⇒ K x = ω 2 M x (-\omega^2 M + K)x = 0 \Rightarrow Kx = \omega^2 Mx ( − ω 2 M + K ) x = 0 ⇒ K x = ω 2 M x 当 M M M
A x = λ x A x = \lambda x A x = λ x 其中 A = M − 1 K , λ = ω 2 A = M^{-1}K, \lambda = \omega^2 A = M − 1 K , λ = ω 2
特征值与特征向量基本概念回顾
基本定义
特征多项式与特征方程 :
矩阵 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n
ϕ ( λ ) = det ( λ I − A ) = λ n + c 1 λ n − 1 + ⋯ + c n \phi(\lambda) = \det(\lambda I - A) = \lambda^n + c_1\lambda^{n-1} + \cdots + c_n ϕ ( λ ) = det ( λ I − A ) = λ n + c 1 λ n − 1 + ⋯ + c n 特征方程 ϕ ( λ ) = 0 \phi(\lambda)=0 ϕ ( λ ) = 0 λ 1 , … , λ n \lambda_1,\dots,\lambda_n λ 1 , … , λ n λ ( A ) \lambda(A) λ ( A )
特征向量与特征子空间 :
对特征值 λ \lambda λ ( λ I − A ) x = 0 (\lambda I - A)x = 0 ( λ I − A ) x = 0 x x x
代数重数与几何重数 :
代数重数 n j n_j n j λ ~ j \tilde{\lambda}_j λ ~ j
几何重数 k j k_j k j λ ~ j \tilde{\lambda}_j λ ~ j
有如下等价定义:
代数重数 n j n_j n j λ ~ j \tilde{\lambda}_j λ ~ j
几何重数 k j k_j k j λ ~ j \tilde{\lambda}_j λ ~ j
从而可见满足关系:1 ≤ k j ≤ n j 1 \leq k_j \leq n_j 1 ≤ k j ≤ n j
重要定理
迹与行列式 :
设 λ i \lambda_i λ i A A A
∑ j = 1 n λ j = tr ( A ) = ∑ j = 1 n a j j , ∏ j = 1 n λ j = det ( A ) \sum_{j=1}^n \lambda_j = \text{tr}(A) = \sum_{j=1}^n a_{jj}, \quad \prod_{j=1}^n \lambda_j = \det(A) j = 1 ∑ n λ j = tr ( A ) = j = 1 ∑ n a j j , j = 1 ∏ n λ j = det ( A )
转置不变性 :λ ( A ) = λ ( A T ) \lambda(A) = \lambda(A^T) λ ( A ) = λ ( A T )
三角阵特征值 :若 A A A
分块三角阵特征值 :
对分块上三角阵 A = [ A 11 ⋯ ⋱ ] A = \begin{bmatrix} A_{11} & \cdots \\ & \ddots \end{bmatrix} A = [ A 11 ⋯ ⋱ ]
λ ( A ) = ⋃ j = 1 m λ ( A j j ) \lambda(A) = \bigcup_{j=1}^m \lambda(A_{jj}) λ ( A ) = j = 1 ⋃ m λ ( A j j ) 分块下三角阵同理。
相似变换不变性 :
若 B = X − 1 A X B = X^{-1}AX B = X − 1 A X X X X
λ ( A ) = λ ( B ) \lambda(A) = \lambda(B) λ ( A ) = λ ( B ) 若 y y y B B B X y Xy X y A A A
特征值的代数性质 :
设 λ i \lambda_i λ i A A A
c A cA c A c λ i c\lambda_i c λ i A + c I A + cI A + c I λ i + c \lambda_i + c λ i + c A k A^k A k λ i k \lambda_i^k λ i k p ( A ) p(A) p ( A ) p ( λ i ) p(\lambda_i) p ( λ i ) p p p A − 1 A^{-1} A − 1 λ i − 1 \lambda_i^{-1} λ i − 1 A A A
幂法
幂法(Power Method)用于计算矩阵(模)最大特征值以及对应的特征向量。
幂法的数学原理
矩阵模最大的特征值称为主特征值(dominant eigenvalue),对应特征向量为主特征向量。
幂法收敛性 :
设 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n ∣ λ 1 ∣ > ∣ λ 2 ∣ ≥ ∣ λ 3 ∣ ≥ ⋯ ≥ ∣ λ n ∣ |\lambda_1| > |\lambda_2| \ge |\lambda_3| \ge \cdots \ge |\lambda_n| ∣ λ 1 ∣ > ∣ λ 2 ∣ ≥ ∣ λ 3 ∣ ≥ ⋯ ≥ ∣ λ n ∣ λ 1 \lambda_1 λ 1 λ 1 \lambda_1 λ 1 1 1 1
初始向量 x ( 0 ) ∈ R n x^{(0)} \in \mathbb{R}^n x ( 0 ) ∈ R n λ 1 \lambda_1 λ 1
定义迭代:
x ( k ) = A x ( k − 1 ) , k = 1 , 2 , … x^{(k)} = A x^{(k-1)}, \quad k = 1,2,\dots x ( k ) = A x ( k − 1 ) , k = 1 , 2 , … 归一化:
y ( k ) = x ( k ) ∥ x ( k ) ∥ ∞ y^{(k)} = \frac{x^{(k)}}{\|x^{(k)}\|_\infty} y ( k ) = ∥ x ( k ) ∥ ∞ x ( k ) 则:
y ( k ) y^{(k)} y ( k ) λ 1 \lambda_1 λ 1 主特征值可通过下式估计:
λ 1 = lim k → ∞ ( x ( k + 1 ) ) j ( x ( k ) ) j , j = arg max i ∣ ( x ( k ) ) i ∣ \lambda_1 = \lim_{k\to\infty} \frac{(x^{(k+1)})_j}{(x^{(k)})_j}, \quad j = \arg\max_i |(x^{(k)})_i| λ 1 = k → ∞ lim ( x ( k ) ) j ( x ( k + 1 ) ) j , j = arg i max ∣ ( x ( k ) ) i ∣
证明 :
分解 :
对 A A A A = P J P − 1 A=PJP^{-1} A = P J P − 1
J = d i a g ( J 1 , … , J r ) , J i = ( λ i 1 λ i ⋱ ⋱ 1 λ i ) m i , ∑ m i = n . J=\mathrm{diag}(J_1,\dots,J_r),\quad
J_i=\begin{pmatrix}\lambda_i&1&&\\&\lambda_i&\ddots&\\&&\ddots&1\\&&&\lambda_i\end{pmatrix}_{m_i},\quad \sum m_i=n. J = diag ( J 1 , … , J r ) , J i = λ i 1 λ i ⋱ ⋱ 1 λ i m i , ∑ m i = n . 记 z = P − 1 x ( 0 ) = ( z 1 , … , z r ) T z=P^{-1}x^{(0)}=(z_1,\dots,z_r)^{\mathsf T} z = P − 1 x ( 0 ) = ( z 1 , … , z r ) T z i ∈ R m i z_i\in\mathbb R^{m_i} z i ∈ R m i
x ( k ) = P J k z x^{(k)}=PJ^k z x ( k ) = P J k z 对单个块记 J ( λ , m ) = λ I + N J(\lambda,m)=\lambda I+N J ( λ , m ) = λ I + N N m = 0 N^m=0 N m = 0
估阶 :
对 Jordan 块 J ( λ , m ) = λ I + N J(\lambda,m) = \lambda I + N J ( λ , m ) = λ I + N
J ( λ , m ) k = ∑ j = 0 m − 1 ( k j ) λ k − j N j = k m − 1 ( m − 1 ) ! λ k − m + 1 N m − 1 + O ( k m − 2 ∣ λ ∣ k ) J(\lambda,m)^k = \sum_{j=0}^{m-1} \binom{k}{j} \lambda^{k-j} N^j = \frac{k^{m-1}}{(m-1)!}\lambda^{k-m+1}N^{m-1} + O(k^{m-2}|\lambda|^k) J ( λ , m ) k = j = 0 ∑ m − 1 ( j k ) λ k − j N j = ( m − 1 )! k m − 1 λ k − m + 1 N m − 1 + O ( k m − 2 ∣ λ ∣ k ) 其中 O ( ⋅ ) O(\cdot) O ( ⋅ )
作用于 z i z_i z i N m i − 1 z i N^{m_i-1}z_i N m i − 1 z i
∥ J i k z i ∥ = O ( ∣ λ i ∣ k k m i − 1 ) \|J_i^k z_i\| = O(|\lambda_i|^k k^{m_i-1}) ∥ J i k z i ∥ = O ( ∣ λ i ∣ k k m i − 1 ) 对非主块 i ≥ 2 i \geq 2 i ≥ 2 ρ ∈ ( ∣ λ 2 ∣ / ∣ λ 1 ∣ , 1 ) \rho \in (|\lambda_2|/|\lambda_1|, 1) ρ ∈ ( ∣ λ 2 ∣/∣ λ 1 ∣ , 1 ) ∣ λ i ∣ ≤ ρ ∣ λ 1 ∣ |\lambda_i| \leq \rho|\lambda_1| ∣ λ i ∣ ≤ ρ ∣ λ 1 ∣
∥ J i k z i ∥ = O ( ρ k ∣ λ 1 ∣ k k m i − 1 ) = o ( ∣ λ 1 ∣ k k m 1 − 1 ) . \|J_i^k z_i\| = O(\rho^k |\lambda_1|^k k^{m_i-1}) = o(|\lambda_1|^k k^{m_1-1}). ∥ J i k z i ∥ = O ( ρ k ∣ λ 1 ∣ k k m i − 1 ) = o ( ∣ λ 1 ∣ k k m 1 − 1 ) . 对主块 i = 1 i=1 i = 1 w = N m 1 − 1 z 1 w = N^{m_1-1}z_1 w = N m 1 − 1 z 1 x ( 0 ) x^{(0)} x ( 0 ) λ 1 \lambda_1 λ 1 w ≠ 0 w \neq 0 w = 0 N w = 0 Nw = 0 N w = 0 w w w J 1 J_1 J 1
J 1 k z 1 = Θ ( λ 1 k k m 1 − 1 ) w . J_1^k z_1 = \Theta(\lambda_1^k k^{m_1-1}) \, w. J 1 k z 1 = Θ ( λ 1 k k m 1 − 1 ) w . 综上:
∥ x ( k ) ∥ = ∥ P J k z ∥ = Θ ( ∣ λ 1 ∣ k k m 1 − 1 ) x ( k ) = P J k z = [ Θ ( λ 1 k k m 1 − 1 ) P w , o ( ∣ λ 1 ∣ k k m 2 − 1 ) , … ] T \begin{aligned}
\|x^{(k)}\| &= \|PJ^k z\| = \Theta(|\lambda_1|^k k^{m_1-1}) \\
x^{(k)} &= PJ^k z = [\Theta(\lambda_1^k k^{m_1-1}) Pw, \, o(|\lambda_1|^k k^{m_2-1}), \dots]^T
\end{aligned} ∥ x ( k ) ∥ x ( k ) = ∥ P J k z ∥ = Θ ( ∣ λ 1 ∣ k k m 1 − 1 ) = P J k z = [ Θ ( λ 1 k k m 1 − 1 ) P w , o ( ∣ λ 1 ∣ k k m 2 − 1 ) , … ] T
方向收敛 :
归一化并消去非主块:
x ( k ) ∥ x ( k ) ∥ = ( λ 1 ∣ λ 1 ∣ ) k P w ∥ P w ∥ + o ( 1 ) \frac{x^{(k)}}{\|x^{(k)}\|} = \left(\frac{\lambda_1}{|\lambda_1|}\right)^k \frac{Pw}{\|Pw\|} + o(1) ∥ x ( k ) ∥ x ( k ) = ( ∣ λ 1 ∣ λ 1 ) k ∥ P w ∥ P w + o ( 1 ) 令 u 1 = P w / ∥ P w ∥ u_1 = Pw/\|Pw\| u 1 = P w /∥ P w ∥ A A A ∥ ⋅ ∥ ∞ \|\cdot\|_\infty ∥ ⋅ ∥ ∞
y ( k ) = ( λ 1 ∣ λ 1 ∣ ) k u 1 ∥ u 1 ∥ ∞ + o ( 1 ) y^{(k)} = \left(\frac{\lambda_1}{|\lambda_1|}\right)^k \frac{u_1}{\|u_1\|_\infty} + o(1) y ( k ) = ( ∣ λ 1 ∣ λ 1 ) k ∥ u 1 ∥ ∞ u 1 + o ( 1 ) 故 y ( k ) → u 1 y^{(k)} \to u_1 y ( k ) → u 1
特征值估计 :
由 x ( k + 1 ) = A x ( k ) x^{(k+1)} = A x^{(k)} x ( k + 1 ) = A x ( k )
x ( k ) = ∥ x ( k ) ∥ ∞ ( ( λ 1 ∣ λ 1 ∣ ) k u 1 ∥ u 1 ∥ ∞ + o ( 1 ) ) x^{(k)} = \|x^{(k)}\|_\infty \left( \left(\frac{\lambda_1}{|\lambda_1|}\right)^k \frac{u_1}{\|u_1\|_\infty} + o(1) \right) x ( k ) = ∥ x ( k ) ∥ ∞ ( ( ∣ λ 1 ∣ λ 1 ) k ∥ u 1 ∥ ∞ u 1 + o ( 1 ) ) 记 j k = arg max i ∣ ( x ( k ) ) i ∣ j_k = \arg\max\limits_i |(x^{(k)})_i| j k = arg i max ∣ ( x ( k ) ) i ∣ u 1 u_1 u 1 j ∗ j_* j ∗ ∣ ( u 1 ) j ∗ ∣ = ∥ u 1 ∥ ∞ |(u_1)_{j_*}| = \|u_1\|_\infty ∣ ( u 1 ) j ∗ ∣ = ∥ u 1 ∥ ∞ k k k j k = j ∗ j_k = j_* j k = j ∗ ( x ( k ) ) j k = Θ ( ∥ x ( k ) ∥ ∞ ) (x^{(k)})_{j_k} = \Theta(\|x^{(k)}\|_\infty) ( x ( k ) ) j k = Θ ( ∥ x ( k ) ∥ ∞ )
将 x ( k + 1 ) = A x ( k ) x^{(k+1)} = A x^{(k)} x ( k + 1 ) = A x ( k ) j k j_k j k
( x ( k + 1 ) ) j k = λ 1 ( x ( k ) ) j k + ( A x ( k ) − λ 1 x ( k ) ) j k (x^{(k+1)})_{j_k} = \lambda_1 (x^{(k)})_{j_k} + \big( A x^{(k)} - \lambda_1 x^{(k)} \big)_{j_k} ( x ( k + 1 ) ) j k = λ 1 ( x ( k ) ) j k + ( A x ( k ) − λ 1 x ( k ) ) j k 由第 2 部分的阶的估计,非主特征值部分贡献为 o ( ∥ x ( k ) ∥ ∞ ) o(\|x^{(k)}\|_\infty) o ( ∥ x ( k ) ∥ ∞ )
( x ( k + 1 ) ) j k = λ 1 ( x ( k ) ) j k + o ( ∥ x ( k ) ∥ ∞ ) (x^{(k+1)})_{j_k} = \lambda_1 (x^{(k)})_{j_k} + o(\|x^{(k)}\|_\infty) ( x ( k + 1 ) ) j k = λ 1 ( x ( k ) ) j k + o ( ∥ x ( k ) ∥ ∞ ) 两边除以 ( x ( k ) ) j k (x^{(k)})_{j_k} ( x ( k ) ) j k k k k
( x ( k + 1 ) ) j k ( x ( k ) ) j k = λ 1 + o ( ∥ x ( k ) ∥ ∞ ) ( x ( k ) ) j k = λ 1 + o ( ∥ x ( k ) ∥ ∞ ) Θ ( ∥ x ( k ) ∥ ∞ ) = λ 1 + o ( 1 ) \frac{(x^{(k+1)})_{j_k}}{(x^{(k)})_{j_k}}
= \lambda_1 + \frac{o(\|x^{(k)}\|_\infty)}{(x^{(k)})_{j_k}}
= \lambda_1 + \frac{o(\|x^{(k)}\|_\infty)}{\Theta(\|x^{(k)}\|_\infty)}
= \lambda_1 + o(1) ( x ( k ) ) j k ( x ( k + 1 ) ) j k = λ 1 + ( x ( k ) ) j k o ( ∥ x ( k ) ∥ ∞ ) = λ 1 + Θ ( ∥ x ( k ) ∥ ∞ ) o ( ∥ x ( k ) ∥ ∞ ) = λ 1 + o ( 1 ) 取极限即得
lim k → ∞ ( x ( k + 1 ) ) j ( x ( k ) ) j = λ 1 , j = arg max i ∣ ( x ( k ) ) i ∣ \lim_{k\to\infty} \frac{(x^{(k+1)})_j}{(x^{(k)})_j} = \lambda_1, \qquad j = \arg\max_i |(x^{(k)})_i| k → ∞ lim ( x ( k ) ) j ( x ( k + 1 ) ) j = λ 1 , j = arg i max ∣ ( x ( k ) ) i ∣
注 :
非主块贡献为 O ( ρ k ) O(\rho^k) O ( ρ k )
( x ( k + 1 ) ) j ( x ( k ) ) j − λ 1 = O ( ∣ λ 2 λ 1 ∣ k ) \frac{(x^{(k+1)})_j}{(x^{(k)})_j} - \lambda_1
= O\!\left( \left|\dfrac{\lambda_2}{\lambda_1}\right|^k \right) ( x ( k ) ) j ( x ( k + 1 ) ) j − λ 1 = O ( λ 1 λ 2 k ) 幂法的几何直观
设矩阵 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n λ 1 \lambda_1 λ 1 ∣ λ 1 ∣ > ∣ λ 2 ∣ ≥ ∣ λ 3 ∣ ≥ ⋯ |\lambda_1| > |\lambda_2| \ge |\lambda_3| \ge \cdots ∣ λ 1 ∣ > ∣ λ 2 ∣ ≥ ∣ λ 3 ∣ ≥ ⋯ s p a n { u 1 , u 2 } \mathrm{span}\{u_1, u_2\} span { u 1 , u 2 } u 1 u_1 u 1 λ 1 \lambda_1 λ 1 u 2 u_2 u 2 λ 2 \lambda_2 λ 2
假设初始向量 x ( 0 ) x^{(0)} x ( 0 )
x ( 0 ) = a 0 u 1 + b 0 u 2 x^{(0)} = a_0 u_1 + b_0 u_2 x ( 0 ) = a 0 u 1 + b 0 u 2 迭代 k k k
x ( k ) = A k x ( 0 ) = λ 1 k a 0 u 1 + λ 2 k b 0 u 2 x^{(k)} = A^k x^{(0)} = \lambda_1^k a_0 u_1 + \lambda_2^k b_0 u_2 x ( k ) = A k x ( 0 ) = λ 1 k a 0 u 1 + λ 2 k b 0 u 2 由于 ∣ λ 1 ∣ > ∣ λ 2 ∣ |\lambda_1| > |\lambda_2| ∣ λ 1 ∣ > ∣ λ 2 ∣ u 1 u_1 u 1
设 θ k \theta_k θ k x ( k ) x^{(k)} x ( k ) u 1 u_1 u 1
tan θ k = ∣ b k ∣ ∣ a k ∣ = ∣ λ 2 λ 1 ∣ k ⋅ tan θ 0 \tan\theta_k = \frac{|b_k|}{|a_k|} = \left|\frac{\lambda_2}{\lambda_1}\right|^k \cdot \tan\theta_0 tan θ k = ∣ a k ∣ ∣ b k ∣ = λ 1 λ 2 k ⋅ tan θ 0 特征值估计为:
λ 1 ( k ) = ( x ( k + 1 ) ) j ( x ( k ) ) j \lambda_1^{(k)} = \frac{(x^{(k+1)})_j}{(x^{(k)})_j} λ 1 ( k ) = ( x ( k ) ) j ( x ( k + 1 ) ) j 又因为
( x ( k ) ) j = a k + b k ( u 2 ) j ( x ( k + 1 ) ) j = λ 1 a k + λ 2 b k ( u 2 ) j \begin{aligned}
(x^{(k)})_j &= a_k + b_k (u_2)_j \\
(x^{(k+1)})_j &= \lambda_1 a_k + \lambda_2 b_k (u_2)_j
\end{aligned} ( x ( k ) ) j ( x ( k + 1 ) ) j = a k + b k ( u 2 ) j = λ 1 a k + λ 2 b k ( u 2 ) j 因此:
( x ( k + 1 ) ) j ( x ( k ) ) j = λ 1 a k + λ 2 b k ( u 2 ) j a k + b k ( u 2 ) j = λ 1 + λ 2 ⋅ b k a k ( u 2 ) j 1 + b k a k ( u 2 ) j = λ 1 + ( λ 2 − λ 1 ) ⋅ b k a k ( u 2 ) j + o ( b k a k ) \begin{aligned}
\frac{(x^{(k+1)})_j}{(x^{(k)})_j}
&= \frac{\lambda_1 a_k + \lambda_2 b_k (u_2)_j}{a_k + b_k (u_2)_j} \\
&= \frac{\lambda_1 + \lambda_2 \cdot \frac{b_k}{a_k} (u_2)_j}{1 + \frac{b_k}{a_k} (u_2)_j} \\
&= \lambda_1 + (\lambda_2 - \lambda_1) \cdot \frac{b_k}{a_k} (u_2)_j + o(\frac{b_k}{a_k})
\end{aligned} ( x ( k ) ) j ( x ( k + 1 ) ) j = a k + b k ( u 2 ) j λ 1 a k + λ 2 b k ( u 2 ) j = 1 + a k b k ( u 2 ) j λ 1 + λ 2 ⋅ a k b k ( u 2 ) j = λ 1 + ( λ 2 − λ 1 ) ⋅ a k b k ( u 2 ) j + o ( a k b k ) 从而:
λ 1 ( k ) − λ 1 = O ( ∣ λ 2 λ 1 ∣ k ) \lambda_1^{(k)} - \lambda_1
= O\!\left( \left|\dfrac{\lambda_2}{\lambda_1}\right|^k \right) λ 1 ( k ) − λ 1 = O ( λ 1 λ 2 k ) 数值稳定性改进
原始迭代 x ( k ) = A k x ( 0 ) x^{(k)} = A^k x^{(0)} x ( k ) = A k x ( 0 )
∣ λ 1 ∣ > 1 |\lambda_1| > 1 ∣ λ 1 ∣ > 1 ∣ λ 1 ∣ < 1 |\lambda_1| < 1 ∣ λ 1 ∣ < 1
故我们在迭代中用 ∞ \infty ∞
{ y ( k ) = x ( k ) / ∥ x ( k ) ∥ ∞ x ( k + 1 ) = A y ( k ) , k = 0 , 1 , 2 , … \begin{cases}
y^{(k)} = x^{(k)}/\|x^{(k)}\|_\infty \\
x^{(k+1)} = A y^{(k)}
\end{cases}, \quad k=0,1,2,\dots { y ( k ) = x ( k ) /∥ x ( k ) ∥ ∞ x ( k + 1 ) = A y ( k ) , k = 0 , 1 , 2 , … 主特征值估计为 λ 1 ( k ) = ( x ( k ) ) j \lambda_1^{(k)} = (x^{(k)})_j λ 1 ( k ) = ( x ( k ) ) j j = arg max i ∣ ( x ( k ) ) i ∣ j = \arg\max_i |(x^{(k)})_i| j = arg max i ∣ ( x ( k ) ) i ∣
幂法算法实现
k = 0 lambda_old = 0.0 while k < N: k += 1 j = np.argmax(np.abs(x)) lambda_new = x[j] y = x / lambda_new # 归一化 x = A @ y # 迭代 if np.abs(lambda_new - lambda_old) < EPS : break lambda_old = lambda_new 位移幂法
位移幂法的数学原理
注意到幂法收敛速度为:
( x ( k + 1 ) ) j ( x ( k ) ) j − λ 1 = O ( ∣ λ 2 λ 1 ∣ k ) \frac{(x^{(k+1)})_j}{(x^{(k)})_j} - \lambda_1
= O\!\left( \left|\dfrac{\lambda_2}{\lambda_1}\right|^k \right) ( x ( k ) ) j ( x ( k + 1 ) ) j − λ 1 = O ( λ 1 λ 2 k ) 利用特征值平移性质:
若 A u i = λ i u i Au_i = \lambda_i u_i A u i = λ i u i ( A − μ I ) u i = ( λ i − μ ) u i (A - \mu I)u_i = (\lambda_i - \mu)u_i ( A − μ I ) u i = ( λ i − μ ) u i
λ i − μ \lambda_i - \mu λ i − μ A − μ I A - \mu I A − μ I u i u_i u i A − μ I A - \mu I A − μ I
从而可以选择位移 μ \mu μ
∣ λ 2 − μ λ 1 − μ ∣ < ∣ λ 2 λ 1 ∣ \left| \frac{\lambda_2 - \mu}{\lambda_1 - \mu} \right| < \left| \frac{\lambda_2}{\lambda_1} \right| λ 1 − μ λ 2 − μ < λ 1 λ 2 特殊地,对称正定矩阵特征值均为实数,故最优位移为:
μ = 1 2 ( λ 2 + λ n ) \mu = \frac{1}{2}(\lambda_2 + \lambda_n) μ = 2 1 ( λ 2 + λ n ) 位移幂法的几何直观
A − μ I A - \mu I A − μ I μ \mu μ μ \mu μ λ 2 \lambda_2 λ 2 u 2 u_2 u 2 u 1 u_1 u 1
注 :
理论上我们也可以利用这种方法求次特征值。
位移幂法算法实现
实际实现时原点位移值 shift 需要利用特征值分布估计。
k = 0 lambda_old = 0.0 while k < N: k += 1 j = np.argmax(np.abs(x)) lambda_new = x[j] y = x / lambda_new # 归一化 x = A @ y - shift * y # 迭代 if np.abs(lambda_new - lambda_old) < EPS : break lambda_old = lambda_new lambda_old += shift 降阶幂法
降阶幂法的数学原理
假设对称矩阵 A A A
已知主特征值 λ 1 \lambda_1 λ 1 u 1 u_1 u 1
A ( 2 ) = A − λ 1 u 1 u 1 T u 1 T u 1 A^{(2)} = A - \lambda_1 \frac{u_1 u_1^T}{u_1^T u_1} A ( 2 ) = A − λ 1 u 1 T u 1 u 1 u 1 T 则:
A ( 2 ) u 1 = 0 A^{(2)} u_1 = 0 A ( 2 ) u 1 = 0 A ( 2 ) u i = λ i u i A^{(2)} u_i = \lambda_i u_i A ( 2 ) u i = λ i u i i = 2 , 3 , … , n i=2,3,\dots,n i = 2 , 3 , … , n
即 A ( 2 ) A^{(2)} A ( 2 ) 0 , λ 2 , … , λ n 0, \lambda_2, \dots, \lambda_n 0 , λ 2 , … , λ n A ( 2 ) A^{(2)} A ( 2 ) λ 2 , u 2 \lambda_2, u_2 λ 2 , u 2
注 :
降阶法精度不佳,且破坏稀疏性,仅适用于求前几个特征值;实际中多用 Lanczos 等 Krylov 子空间方法。
降阶幂法的几何直观
注意到 u 1 u 1 T u 1 T u 1 \dfrac{u_1 u_1^T}{u_1^T u_1} u 1 T u 1 u 1 u 1 T u 1 u_1 u 1 A ( 2 ) A^{(2)} A ( 2 ) A ( 2 ) A^{(2)} A ( 2 )
反幂法
反幂法(Inverse Power Method)用于计算矩阵(模)最小特征值以及对应的特征向量。
反幂法的数学原理
适用于非奇异矩阵。由特征值倒数性质:若 A u i = λ i u i Au_i = \lambda_i u_i A u i = λ i u i A − 1 u i = λ i − 1 u i A^{-1}u_i = \lambda_i^{-1} u_i A − 1 u i = λ i − 1 u i
因此,对 A − 1 A^{-1} A − 1 ∣ λ n ∣ |\lambda_n| ∣ λ n ∣
为避免显式求逆,可以将 x ( k ) = A − 1 x ( k − 1 ) x^{(k)} = A^{-1} x^{(k-1)} x ( k ) = A − 1 x ( k − 1 )
A x ( k ) = x ( k − 1 ) A x^{(k)} = x^{(k-1)} A x ( k ) = x ( k − 1 ) 反幂法算法实现
k = 0 _, L, U = lu(A) # 预计算 LU 分解 lambda_old = 1e16 # 初始极大值 while k < N: k += 1 j = np.argmax(np.abs(x)) lambda_new = x[j] y = x / lambda_new # 归一化 # LU 分解法解 Ax = y z = solve_triangular(L, y, lower = True ) # 先解 Lz = y x = solve_triangular(U, z, lower = False ) # 再解 Ux = z if np.abs( 1 / lambda_new - 1 / lambda_old) < EPS : break lambda_old = lambda_new lambda_old = 1 / lambda_old 位移反幂法
结合位移技术,我们可以求已知近似特征值 λ ∗ \lambda^* λ ∗
首先构造 B = A − λ ∗ I B = A - \lambda^* I B = A − λ ∗ I B B B μ \mu μ
λ = μ + λ ∗ \lambda = \mu + \lambda^* λ = μ + λ ∗ 由于 ∣ λ − λ ∗ ∣ ≪ ∣ λ i − λ ∗ ∣ |\lambda - \lambda^*| \ll |\lambda_i - \lambda^*| ∣ λ − λ ∗ ∣ ≪ ∣ λ i − λ ∗ ∣
Jacobi 法
Jacobi 法用于计算实对称矩阵的所有特征值以及对应的特征向量。
核心思想
对实对称矩阵 A A A Q Q Q Q T A Q = D Q^T A Q = D Q T A Q = D 2D 正交变换 逐步消除非对角元。
2×2 子问题求解
对子矩阵 [ a p p a p q a p q a q q ] \begin{bmatrix} a_{pp} & a_{pq} \\ a_{pq} & a_{qq} \end{bmatrix} [ a pp a pq a pq a q q ]
Q = [ cos θ − sin θ sin θ cos θ ] Q = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} Q = [ cos θ sin θ − sin θ cos θ ] 要求 Q T A Q Q^T A Q Q T A Q ( p , q ) (p,q) ( p , q )
a p q ( 1 ) = a q q − a p p 2 sin 2 θ + a p q cos 2 θ = 0 ⇒ cot 2 θ = a p p − a q q 2 a p q a_{pq}^{(1)} = \frac{a_{qq} - a_{pp}}{2} \sin 2\theta + a_{pq} \cos 2\theta = 0
\Rightarrow \cot 2\theta = \frac{a_{pp} - a_{qq}}{2a_{pq}} a pq ( 1 ) = 2 a q q − a pp sin 2 θ + a pq cos 2 θ = 0 ⇒ cot 2 θ = 2 a pq a pp − a q q 解得:
τ = a p p − a q q 2 a p q t = − sign ( τ ) ∣ τ ∣ + 1 + τ 2 c = 1 1 + t 2 s = c t \begin{aligned}
\tau &= \frac{a_{pp} - a_{qq}}{2a_{pq}} \\
t &= -\frac{\text{sign}(\tau)}{|\tau| + \sqrt{1+\tau^2}} \\
c &= \frac{1}{\sqrt{1+t^2}} \\
s &= ct
\end{aligned} τ t c s = 2 a pq a pp − a q q = − ∣ τ ∣ + 1 + τ 2 sign ( τ ) = 1 + t 2 1 = c t 注 :直接用反三角函数计算会数值不稳定,所以用上述方法避免三角函数计算。
n×n 矩阵求解
构造 Q p q Q_{pq} Q pq ( p , p ) , ( p , q ) , ( q , p ) , ( q , q ) (p,p),(p,q),(q,p),(q,q) ( p , p ) , ( p , q ) , ( q , p ) , ( q , q )
A ( 1 ) = Q p q T A Q p q A^{(1)} = Q_{pq}^T A Q_{pq} A ( 1 ) = Q pq T A Q pq 迭代后非对角元 a p q ( 1 ) = 0 a_{pq}^{(1)} = 0 a pq ( 1 ) = 0
收敛性证明
定义非对角元平方和:
∥ A ∥ F 2 − tr ( A 2 ) = ∑ i ≠ j a i j 2 \|A\|_F^2 - \text{tr}(A^2) = \sum_{i\neq j} a_{ij}^2 ∥ A ∥ F 2 − tr ( A 2 ) = i = j ∑ a ij 2 由 Frobenius 范数不变:
∑ i ( a i i ( k + 1 ) ) 2 + ∑ i ≠ j ( a i j ( k + 1 ) ) 2 = ∑ i ( a i i ( k ) ) 2 + ∑ i ≠ j ( a i j ( k ) ) 2 \sum_i (a_{ii}^{(k+1)})^2 + \sum_{i\neq j} (a_{ij}^{(k+1)})^2 = \sum_i (a_{ii}^{(k)})^2 + \sum_{i\neq j} (a_{ij}^{(k)})^2 i ∑ ( a ii ( k + 1 ) ) 2 + i = j ∑ ( a ij ( k + 1 ) ) 2 = i ∑ ( a ii ( k ) ) 2 + i = j ∑ ( a ij ( k ) ) 2 旋转仅改变 a p p , a q q , a p q , a q p a_{pp}, a_{qq}, a_{pq}, a_{qp} a pp , a q q , a pq , a q p ( a p p ( k + 1 ) ) 2 + ( a q q ( k + 1 ) ) 2 = ( a p p ( k ) ) 2 + ( a q q ( k ) ) 2 + 2 ( a p q ( k ) ) 2 (a_{pp}^{(k+1)})^2 + (a_{qq}^{(k+1)})^2 = (a_{pp}^{(k)})^2 + (a_{qq}^{(k)})^2 + 2(a_{pq}^{(k)})^2 ( a pp ( k + 1 ) ) 2 + ( a q q ( k + 1 ) ) 2 = ( a pp ( k ) ) 2 + ( a q q ( k ) ) 2 + 2 ( a pq ( k ) ) 2
代入得:
∑ i ≠ j ( a i j ( k + 1 ) ) 2 = ∑ i ≠ j ( a i j ( k ) ) 2 − 2 ( a i j ( k ) ) 2 \sum_{i\neq j} (a_{ij}^{(k+1)})^2 = \sum_{i\neq j} (a_{ij}^{(k)})^2 - 2(a_{ij}^{(k)})^2 i = j ∑ ( a ij ( k + 1 ) ) 2 = i = j ∑ ( a ij ( k ) ) 2 − 2 ( a ij ( k ) ) 2 选择最大非对角元 ∣ a p q ∣ |a_{pq}| ∣ a pq ∣
∑ i ≠ j ( a i j ( k + 1 ) ) 2 ≤ ( 1 − 2 n ( n − 1 ) ) ∑ i ≠ j ( a i j ( k ) ) 2 \sum_{i\neq j} (a_{ij}^{(k+1)})^2 \leq \left(1 - \frac{2}{n(n-1)}\right) \sum_{i\neq j} (a_{ij}^{(k)})^2 i = j ∑ ( a ij ( k + 1 ) ) 2 ≤ ( 1 − n ( n − 1 ) 2 ) i = j ∑ ( a ij ( k ) ) 2 故当 k → ∞ k\to\infty k → ∞ ∑ i ≠ j ( a i j ( k ) ) 2 → 0 \sum_{i\neq j} (a_{ij}^{(k)})^2 \to 0 ∑ i = j ( a ij ( k ) ) 2 → 0
注 :可以把 Frobenius 范数理解为能量,通过一次变换会将能量集中于对角线,从而实现收敛。
Jacobi 法算法实现
选择最大非对角元 ∣ a i j ∣ |a_{ij}| ∣ a ij ∣
计算旋转角 θ \theta θ
更新 A ← Q i j T A Q i j A \leftarrow Q_{ij}^T A Q_{ij} A ← Q ij T A Q ij
累积正交矩阵 V ← V Q i j V \leftarrow V Q_{ij} V ← V Q ij
重复直至非对角元足够小
k = 0 n = A.shape[ 0 ] V = np.eye(n) while k < N: k += 1 # 选最大非对角元 p, q = 0 , 1 max_off = 0 for i in range (n): for j in range (i + 1 , n): if abs (A[i, j]) > max_off: max_off = abs (A[i, j]) p, q = i, j if max_off < EPS : break # 计算旋转参数 tau = (A[p, p] - A[q, q]) / ( 2 * A[p, q]) if tau >= 0 : t = - 1 / (tau + np.sqrt( 1 + tau ** 2 )) else : t = 1 / ( - tau + np.sqrt( 1 + tau ** 2 )) c = 1 / np.sqrt( 1 + t ** 2 ) s = c * t # 更新 A a_pp, a_qq, a_pq = A[p, p], A[q, q], A[p, q] A[p, p] = c ** 2 * a_pp + s ** 2 * a_qq - 2 * s * c * a_pq A[q, q] = s ** 2 * a_pp + c ** 2 * a_qq + 2 * s * c * a_pq A[p, q] = A[q, p] = 0 for i in range (n): if i != p and i != q: a_ip, a_iq = A[i, p], A[i, q] A[i, p] = A[p, i] = c * a_ip - s * a_iq A[i, q] = A[q, i] = s * a_ip + c * a_iq # 累积 V for i in range (n): v_ip, v_iq = V[i, p], V[i, q] V[i, p] = c * v_ip - s * v_iq V[i, q] = s * v_ip + c * v_iq eigvals = np.diag(A) idx = np.argsort(eigvals)[:: - 1 ] # 从大到小排序 eigvals = eigvals[idx] eigvecs = V[:, idx] 注 :
现代实现多按固定顺序遍历所有 ( i , j ) (i,j) ( i , j )
方法对比与适用场景
方法 适用矩阵 目标特征值 计算复杂度 幂法 唯一主特征值 最大模特征值 O ( n 2 ) O(n^2) O ( n 2 ) 位移幂法 唯一主特征值 离 μ \mu μ O ( n 2 ) O(n^2) O ( n 2 ) 降阶幂法 对称矩阵 前 k k k O ( k n 3 ) O(kn^3) O ( k n 3 ) 反幂法 非奇异矩阵 最小模特征值 O ( n 3 ) O(n^3) O ( n 3 ) O ( n 2 ) O(n^2) O ( n 2 ) 位移反幂法 非奇异矩阵 离 μ \mu μ O ( n 3 ) O(n^3) O ( n 3 ) O ( n 2 ) O(n^2) O ( n 2 ) Jacobi 法 实对称矩阵 所有特征值 未优化 O ( n 4 ) O(n^4) O ( n 4 )