LU 分解概述
定义
LU 分解是将一个方阵 A A A L L L U U U
A = L U A = LU A = LU 其中:
L L L U U U
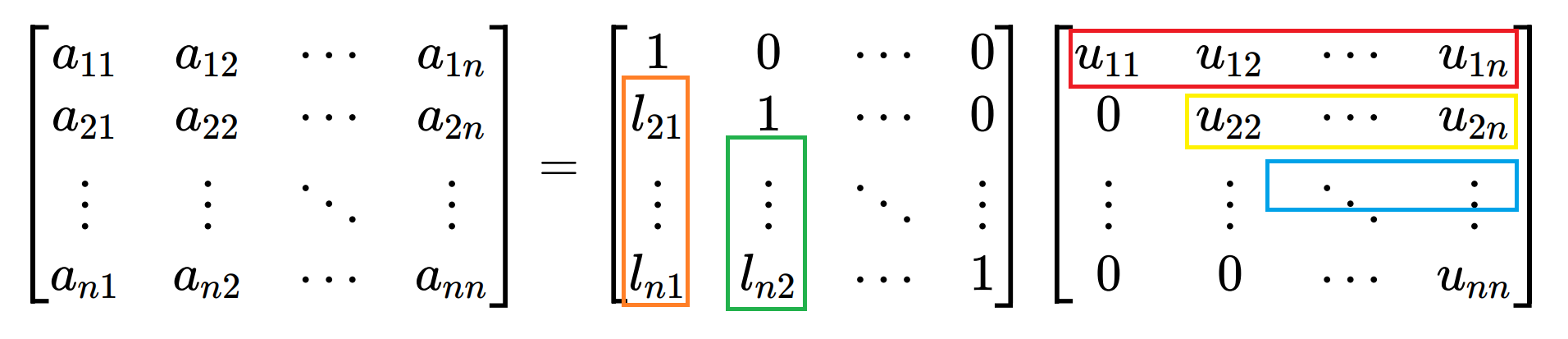
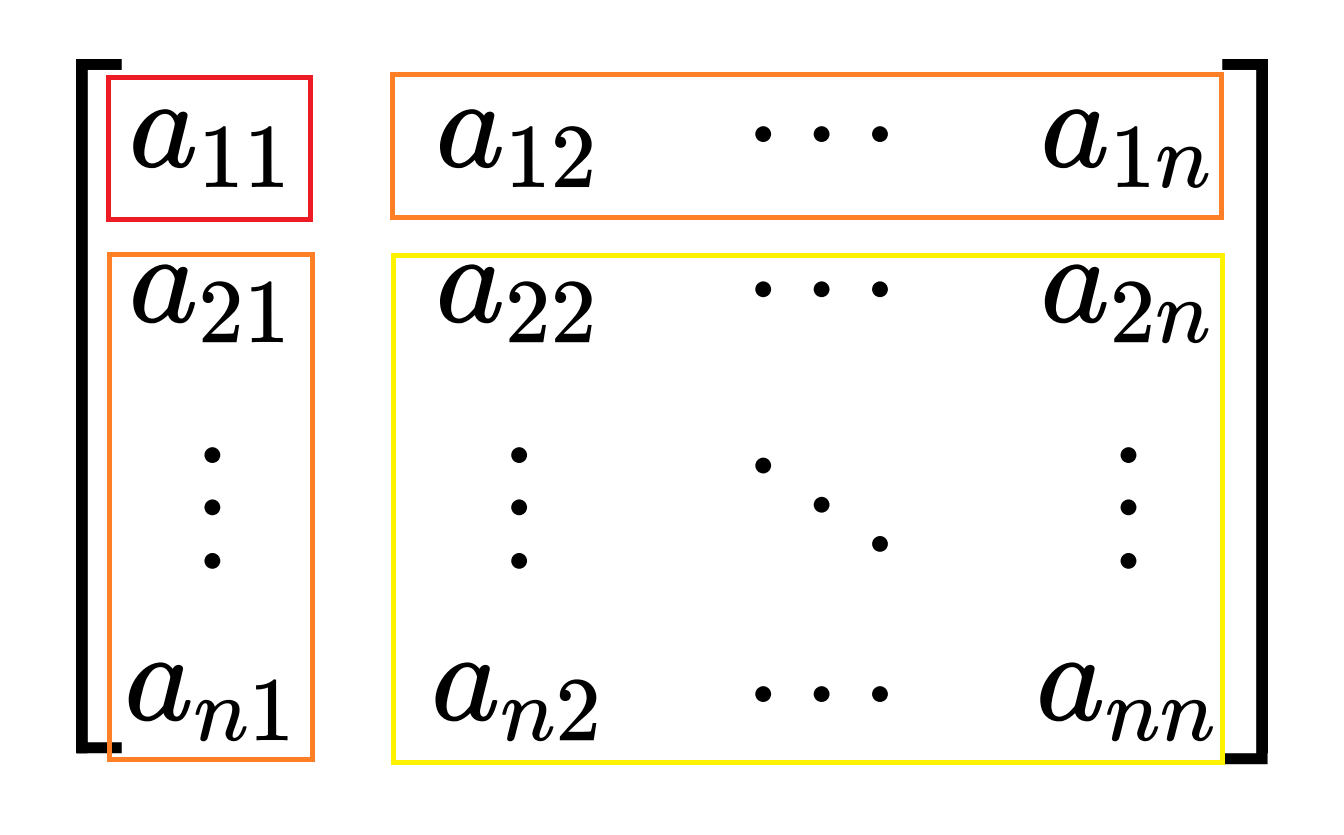
注 :若不加限制,LU 分解不唯一。为保证唯一性,以下采用单位下三角矩阵 形式,即:
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] = [ 1 0 ⋯ 0 l 21 1 ⋯ 0 ⋮ ⋮ ⋱ ⋮ l n 1 l n 2 ⋯ 1 ] [ u 11 u 12 ⋯ u 1 n 0 u 22 ⋯ u 2 n ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ u n n ] \begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 & \cdots & 0 \\
l_{21} & 1 & \cdots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
l_{n1} & l_{n2} & \cdots & 1
\end{bmatrix}
\begin{bmatrix}
u_{11} & u_{12} & \cdots & u_{1n} \\
0 & u_{22} & \cdots & u_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & u_{nn}
\end{bmatrix} a 11 a 21 ⋮ a n 1 a 12 a 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ a 1 n a 2 n ⋮ a nn = 1 l 21 ⋮ l n 1 0 1 ⋮ l n 2 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ 1 u 11 0 ⋮ 0 u 12 u 22 ⋮ 0 ⋯ ⋯ ⋱ ⋯ u 1 n u 2 n ⋮ u nn 利用 LU 分解求解线性方程组
给定线性方程组 A x = b Ax=b A x = b A = L U A=LU A = LU
前向代入(Forward Substitution) :求解 L y = b Ly = b L y = b
y i = b i − ∑ j = 1 i − 1 l i j y j , i = 1 , 2 , … , n y_i = b_i - \sum_{j=1}^{i-1} l_{ij}y_j, \quad i=1,2,\dots,n y i = b i − j = 1 ∑ i − 1 l ij y j , i = 1 , 2 , … , n
后向代入(Backward Substitution) :求解 U x = y Ux = y U x = y
x i = 1 u i i ( y i − ∑ j = i + 1 n u i j x j ) , i = n , n − 1 , … , 1 x_i = \frac{1}{u_{ii}}\left(y_i - \sum_{j=i+1}^{n} u_{ij}x_j\right), \quad i=n,n-1,\dots,1 x i = u ii 1 ( y i − j = i + 1 ∑ n u ij x j ) , i = n , n − 1 , … , 1
从而我们只需给出 LU 分解即可完成线性方程组的求解。
注 :
与 Gauss 消去法相比,LU 分解将消元过程与回代过程分离,便于多次求解同一系数矩阵的方程组(只需一次分解,多次代入)。并且消元是 O ( n 3 ) O(n^3) O ( n 3 ) O ( n 2 ) O(n^2) O ( n 2 )
LU 分解
数学基础:LU 分解的存在唯一性
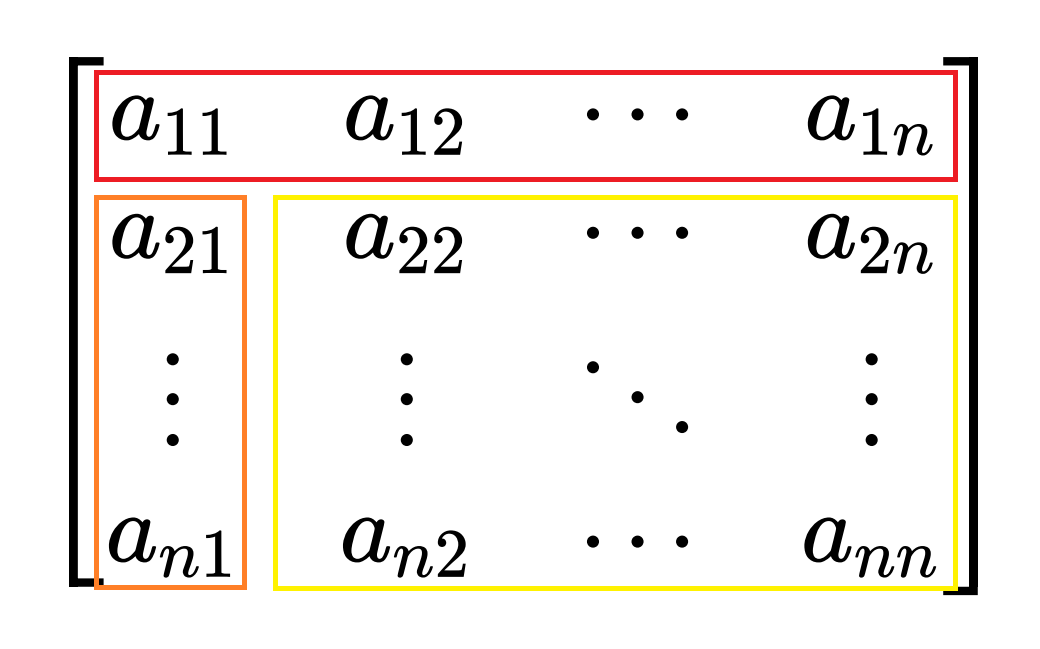
矩阵 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n L L L A A A k k k k = 1 , 2 , … , n − 1 k=1,2,\dots,n-1 k = 1 , 2 , … , n − 1
证明 :
以下 A k A_k A k L k L_k L k U k U_k U k A A A L L L U U U k k k n = 1 n=1 n = 1 n = 1 , 2 , … , k − 1 n=1, 2, \dots, k-1 n = 1 , 2 , … , k − 1 n = k n=k n = k
A k = [ A k − 1 c ⊤ d a k k ] A_k
=
\begin{bmatrix}
A_{k-1} & c^\top \\
d & a_{kk} \\
\end{bmatrix} A k = [ A k − 1 d c ⊤ a k k ] 其 LU 分解可写成
A k = [ A k − 1 c ⊤ d a k k ] = [ L k − 1 0 l 1 ] [ U k − 1 u ⊤ 0 u k k ] A_k
=
\begin{bmatrix}
A_{k-1} & c^\top \\
d & a_{kk} \\
\end{bmatrix}
=
\begin{bmatrix}
L_{k-1} & 0 \\
l & 1 \\
\end{bmatrix}
\begin{bmatrix}
U_{k-1} & u^\top \\
0 & u_{kk} \\
\end{bmatrix} A k = [ A k − 1 d c ⊤ a k k ] = [ L k − 1 l 0 1 ] [ U k − 1 0 u ⊤ u k k ] 也即
{ A k − 1 = L k − 1 U k − 1 c ⊤ = L k − 1 u ⊤ d = l U k − 1 a k k = l u ⊤ + u k k (1) \begin{cases}
A_{k-1} = L_{k-1} U_{k-1} \\
c^\top = L_{k-1} u^\top \\
d = l U_{k-1} \\
a_{kk} = l u^\top + u_{kk}
\end{cases}
\tag{1} ⎩ ⎨ ⎧ A k − 1 = L k − 1 U k − 1 c ⊤ = L k − 1 u ⊤ d = l U k − 1 a k k = l u ⊤ + u k k ( 1 ) 则 LU 分解存在且唯一等价于方程组 ( 1 ) (1) ( 1 )
充分性 :
由条件和归纳知 A k − 1 A_{k-1} A k − 1 L k − 1 L_{k-1} L k − 1 U k − 1 U_{k-1} U k − 1 det ( A k − 1 ) ≠ 0 \det(A_{k-1}) \neq 0 det ( A k − 1 ) = 0 L k − 1 L_{k-1} L k − 1 U k − 1 U_{k-1} U k − 1 ( 1 ) (1) ( 1 )
A k = [ L k − 1 0 − l U k − 1 − 1 1 ] [ U k − 1 L k − 1 − 1 u ⊤ 0 a k k − l U k − 1 − 1 L k − 1 − 1 u ⊤ ] A_k
=
\begin{bmatrix}
L_{k-1} & 0 \\
-l U_{k-1}^{-1} & 1 \\
\end{bmatrix}
\begin{bmatrix}
U_{k-1} & L_{k-1}^{-1} u^\top \\
0 & a_{kk} - l U_{k-1}^{-1} L_{k-1}^{-1} u^\top \\
\end{bmatrix} A k = [ L k − 1 − l U k − 1 − 1 0 1 ] [ U k − 1 0 L k − 1 − 1 u ⊤ a k k − l U k − 1 − 1 L k − 1 − 1 u ⊤ ] 本质上就是简单的行列变换消元。
必要性 :
由条件知方程 ( 1 ) (1) ( 1 ) L k − 1 L_{k-1} L k − 1 U k − 1 U_{k-1} U k − 1 A k − 1 A_{k-1} A k − 1
注 :
我们证明时不需要 A A A
若某顺序主子式为 0,但主元位置可通过行交换(列主元)避免为 0,则可进行PLU分解 (P A = L U PA = LU P A = LU P P P
LU 分解计算公式
u k j = a k j − ∑ m = 1 k − 1 l k m u m j , j = k , k + 1 , … , n u_{kj} = a_{kj} - \sum_{m=1}^{k-1} l_{km}u_{mj}, \quad j=k,k+1,\dots,n u k j = a k j − m = 1 ∑ k − 1 l k m u mj , j = k , k + 1 , … , n l i k = 1 u k k ( a i k − ∑ m = 1 k − 1 l i m u m k ) , i = k + 1 , k + 2 , … , n l_{ik} = \frac{1}{u_{kk}}\left(a_{ik} - \sum_{m=1}^{k-1} l_{im}u_{mk}\right), \quad i=k+1,k+2,\dots,n l ik = u k k 1 ( a ik − m = 1 ∑ k − 1 l im u mk ) , i = k + 1 , k + 2 , … , n 证明 :
从 A = L U A = LU A = LU 逐元素比较 来推导即可。
矩阵乘法:
a i j = ( L U ) i j = ∑ m = 1 n l i m u m j . a_{ij} = (LU)_{ij} = \sum_{m=1}^n l_{im} u_{mj}. a ij = ( LU ) ij = m = 1 ∑ n l im u mj . 由于 L L L l i m = 0 l_{im} = 0 l im = 0 m > i m > i m > i U U U u m j = 0 u_{mj} = 0 u mj = 0 m > j m > j m > j min ( i , j ) \min(i, j) min ( i , j )
a i j = ∑ m = 1 min ( i , j ) l i m u m j . a_{ij} = \sum_{m=1}^{\min(i, j)} l_{im} u_{mj}. a ij = m = 1 ∑ m i n ( i , j ) l im u mj .
情形 1:i ≤ j i \le j i ≤ j U U U i ≤ j i \le j i ≤ j min ( i , j ) = i \min(i, j) = i min ( i , j ) = i
a i j = ∑ m = 1 i l i m u m j = ∑ m = 1 i − 1 l i m u m j + l i i u i j . a_{ij} = \sum_{m=1}^{i} l_{im} u_{mj} = \sum_{m=1}^{i-1} l_{im} u_{mj} + l_{ii} u_{ij}. a ij = m = 1 ∑ i l im u mj = m = 1 ∑ i − 1 l im u mj + l ii u ij . 因为 L L L l i i = 1 l_{ii} = 1 l ii = 1 i i i k k k
u k j = a k j − ∑ m = 1 k − 1 l k m u m j , j = k , k + 1 , … , n . u_{kj} = a_{kj} - \sum_{m=1}^{k-1} l_{km} u_{mj}, \quad j = k, k+1, \dots, n. u k j = a k j − m = 1 ∑ k − 1 l k m u mj , j = k , k + 1 , … , n .
情形 2:i > j i > j i > j L L L i > j i > j i > j min ( i , j ) = j \min(i, j) = j min ( i , j ) = j
a i j = ∑ m = 1 j l i m u m j = ∑ m = 1 j − 1 l i m u m j + l i j u j j . a_{ij} = \sum_{m=1}^{j} l_{im} u_{mj} = \sum_{m=1}^{j-1} l_{im} u_{mj} + l_{ij} u_{jj}. a ij = m = 1 ∑ j l im u mj = m = 1 ∑ j − 1 l im u mj + l ij u j j . 用 k k k j j j
l i k = 1 u k k ( a i k − ∑ m = 1 k − 1 l i m u m k ) , i = k + 1 , k + 2 , … , n . l_{ik} = \frac{1}{u_{kk}} \left( a_{ik} - \sum_{m=1}^{k-1} l_{im} u_{mk} \right), \quad i = k+1, k+2, \dots, n. l ik = u k k 1 ( a ik − m = 1 ∑ k − 1 l im u mk ) , i = k + 1 , k + 2 , … , n .
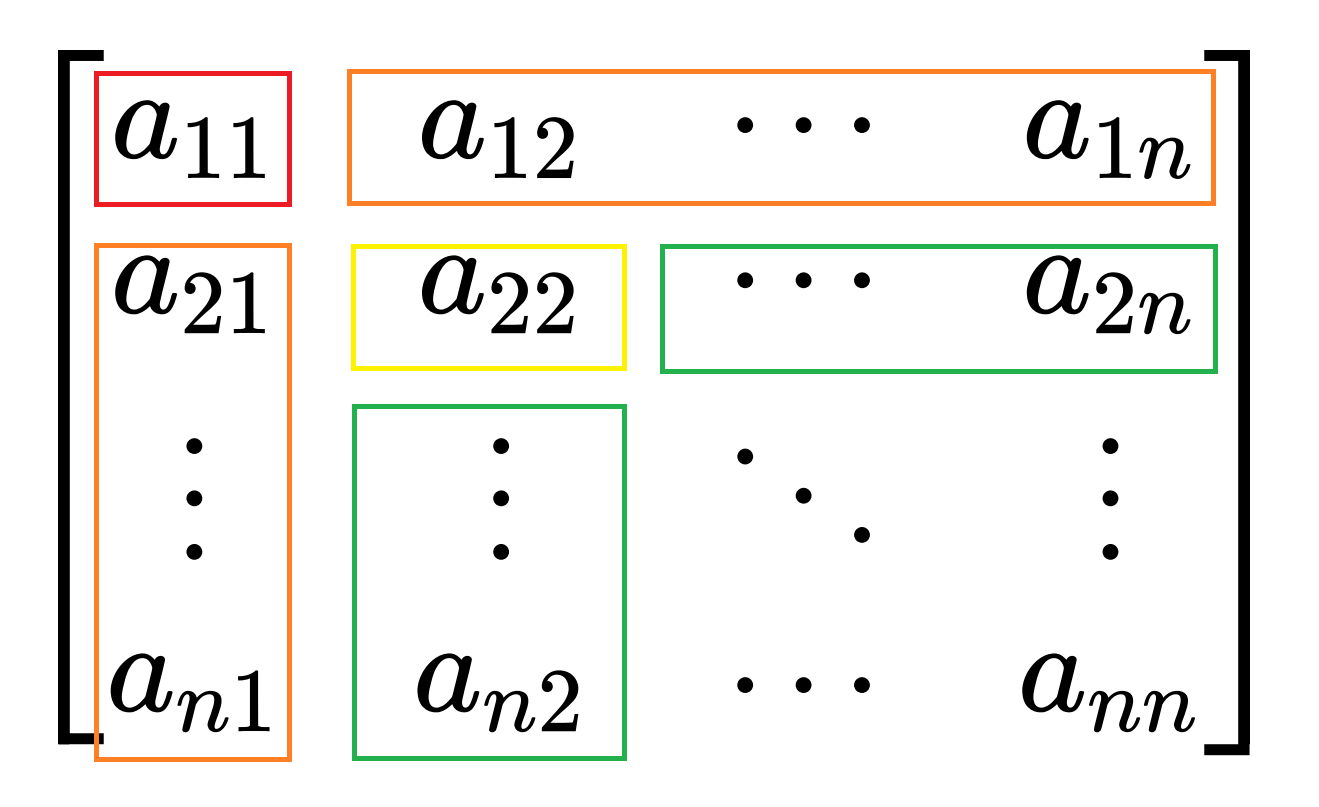
实际操作时应按照下图所示的红橙黄绿蓝顺序依次求解。也即先由上式求出 u 1 u^1 u 1 l 1 l_1 l 1 u 2 u^2 u 2
图1:LU 分解求解顺序
LU 分解代码
标准 LU 分解
for k in range (n): # 枚举 U 的行,同时也是枚举 L 的列 for j in range (k, n): # 枚举 U 的列 U[k, j] = A[k, j] for m in range (k - 1 ): U[k, j] = U[k, j] - L[k, m] * U[m, j] for i in range (k + 1 , n): # 枚举 L 的行 L[i, k] = A[i, k] for m in range (k - 1 ): L[i, k] = L[i, k] - L[i, m] * U[m, k] L[i, k] = L[i, k] / U[k, k] 注 :标准算法需要额外存储空间。实际中常采用原位存储 优化,即将 L L L U U U A A A
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] ⇒ [ u 11 u 12 ⋯ u 1 n l 21 u 22 ⋯ u 2 n ⋮ ⋮ ⋱ ⋮ l n 1 l n 2 ⋯ u n n ] \begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
u_{11} & u_{12} & \cdots & u_{1n} \\
l_{21} & u_{22} & \cdots & u_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
l_{n1} & l_{n2} & \cdots & u_{nn}
\end{bmatrix} a 11 a 21 ⋮ a n 1 a 12 a 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ a 1 n a 2 n ⋮ a nn ⇒ u 11 l 21 ⋮ l n 1 u 12 u 22 ⋮ l n 2 ⋯ ⋯ ⋱ ⋯ u 1 n u 2 n ⋮ u nn 原位存储 LU 分解
由此算法可以更清晰地看到求解顺序。
for k in range (n): # 枚举 U 的行,同时也是枚举 L 的列 for j in range (k, n): # 枚举 U 的列 for m in range (k - 1 ): A[k, j] = A[k, j] - A[k, m] * A[m, j] for i in range (k + 1 , n): # 枚举 L 的行 for m in range (k - 1 ): A[i, k] = A[i, k] - A[i, m] * A[m, k] A[i, k] = A[i, k] / A[k, k] 也即:
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] ⇒ [ u 11 u 12 ⋯ u 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] ⇒ [ u 11 u 12 ⋯ u 1 n l 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ l n 1 a n 2 ⋯ a n n ] ⇒ [ u 11 u 12 ⋯ u 1 n l 21 u 22 ⋯ u 2 n ⋮ ⋮ ⋱ ⋮ l n 1 a n 2 ⋯ a n n ] \begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
u_{11} & u_{12} & \cdots & u_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
u_{11} & u_{12} & \cdots & u_{1n} \\
l_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
l_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\Rightarrow
\begin{bmatrix}
u_{11} & u_{12} & \cdots & u_{1n} \\
l_{21} & u_{22} & \cdots & u_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
l_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix} a 11 a 21 ⋮ a n 1 a 12 a 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ a 1 n a 2 n ⋮ a nn ⇒ u 11 a 21 ⋮ a n 1 u 12 a 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ u 1 n a 2 n ⋮ a nn ⇒ u 11 l 21 ⋮ l n 1 u 12 a 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ u 1 n a 2 n ⋮ a nn ⇒ u 11 l 21 ⋮ l n 1 u 12 u 22 ⋮ a n 2 ⋯ ⋯ ⋱ ⋯ u 1 n u 2 n ⋮ a nn 递归的 LU 分解
基于分块矩阵思想,将 A A A
A = [ a 11 u ⊤ l B ] = [ 1 0 l / a 11 I n − 1 ] [ 1 0 0 B − l u ⊤ / a 11 ] [ a 11 u ⊤ 0 I n − 1 ] A = \begin{bmatrix}
a_{11} & \mathbf{u}^\top \\
\mathbf{l} & B
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 \\
\mathbf{l}/a_{11} & I_{n-1}
\end{bmatrix}
\begin{bmatrix}
1 & 0 \\
0 & B - \mathbf{l}\mathbf{u}^\top/a_{11}
\end{bmatrix}
\begin{bmatrix}
a_{11} & \mathbf{u}^\top \\
0 & I_{n-1}
\end{bmatrix} A = [ a 11 l u ⊤ B ] = [ 1 l / a 11 0 I n − 1 ] [ 1 0 0 B − l u ⊤ / a 11 ] [ a 11 0 u ⊤ I n − 1 ] 其中 B − l u ⊤ / a 11 B - \mathbf{l}\mathbf{u}^\top/a_{11} B − l u ⊤ / a 11 a 11 a_{11} a 11 Schur 补 ,其 LU 分解与原矩阵的 LU 分解递归相关。
这是因为若 Schur 补也能够 LU 分解,即若有 B − l u ⊤ / a 11 = L n − 1 U n − 1 B - \mathbf{l}\mathbf{u}^\top/a_{11} = L_{n-1} U_{n-1} B − l u ⊤ / a 11 = L n − 1 U n − 1
A = [ a 11 u ⊤ l B ] = [ 1 0 l / a 11 L n − 1 ] [ a 11 u ⊤ 0 U n − 1 ] A = \begin{bmatrix}
a_{11} & \mathbf{u}^\top \\
\mathbf{l} & B
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 \\
\mathbf{l}/a_{11} & L_{n-1}
\end{bmatrix}
\begin{bmatrix}
a_{11} & \mathbf{u}^\top \\
0 & U_{n-1}
\end{bmatrix} A = [ a 11 l u ⊤ B ] = [ 1 l / a 11 0 L n − 1 ] [ a 11 0 u ⊤ U n − 1 ] 原位存储的递归算法 :
实际上每一递归步都是按照红橙黄的顺序进行计算,其中红橙色区域计算得到的是最终值,而黄色区域计算得到的是中间值。
for k in range (n - 1 ): # 递归的第 k 步,最后一步不用计算 # 红色区域不需计算 for i in range (k + 1 , n): # 计算橙色区域 A[i, k] = A[i, k] / A[k, k] for i in range (k + 1 , n): # 计算黄色区域 for j in range (k + 1 , n): A[i, j] = A[i, j] - A[i, k] * A[k, j]
图2:递归 LU 分解求解顺序
向量化的递归算法 :
针对按行或按列存储的数组分别进行优化,主要是黄色区域的更新可以考虑内存访问方式(还有 ICS 的事 OoO):
按行存储 :
for k in range (n - 1 ): # 递归的第 k 步,最后一步不用计算 # 红色区域不需计算 A[k + 1 :n, k] = A[k + 1 :n, k] / A[k, k] # 计算橙色区域 for i in range (k + 1 , n): # 计算黄色区域 A[i, k + 1 :n] = A[i, k + 1 :n] - A[i, k] * A[k, k + 1 :n] 按列存储 :
for k in range (n - 1 ): # 递归的第 k 步,最后一步不用计算 # 红色区域不需计算 A[k + 1 :n, k] = A[k + 1 :n, k] / A[k, k] # 计算橙色区域 for j in range (k + 1 , n): # 计算黄色区域 A[k + 1 :n, j] = A[k + 1 :n, j] - A[k + 1 :n, k] * A[k, j] 注 :
向量化操作能充分利用 CPU 的向量指令集(如SSE、AVX),从而加速运算。
复杂度分析
针对原位存储 LU 分解而言:
时间复杂度 :乘除法次数为 ∑ k = 1 n − 1 2 ( n − k ) k + n ≈ n 3 / 3 \sum_{k=1}^{n-1} 2(n-k)k + n \approx n^3/3 ∑ k = 1 n − 1 2 ( n − k ) k + n ≈ n 3 /3 O ( n 3 ) O(n^3) O ( n 3 ) 空间复杂度 :原位存储只需 O ( n 2 ) O(n^2) O ( n 2 )
带状矩阵的 LU 分解
带状矩阵定义
下带宽 p p p :若 i > j + p i > j + p i > j + p a i j = 0 a_{ij} = 0 a ij = 0 上带宽 q q q :若 j > i + q j > i + q j > i + q a i j = 0 a_{ij} = 0 a ij = 0
常见类型:
矩阵结构 下带宽 上带宽 对角矩阵 0 0 上三角矩阵 0 n − 1 n-1 n − 1 下三角矩阵 n − 1 n-1 n − 1 0 三对角矩阵 1 1
带状矩阵的压缩存储
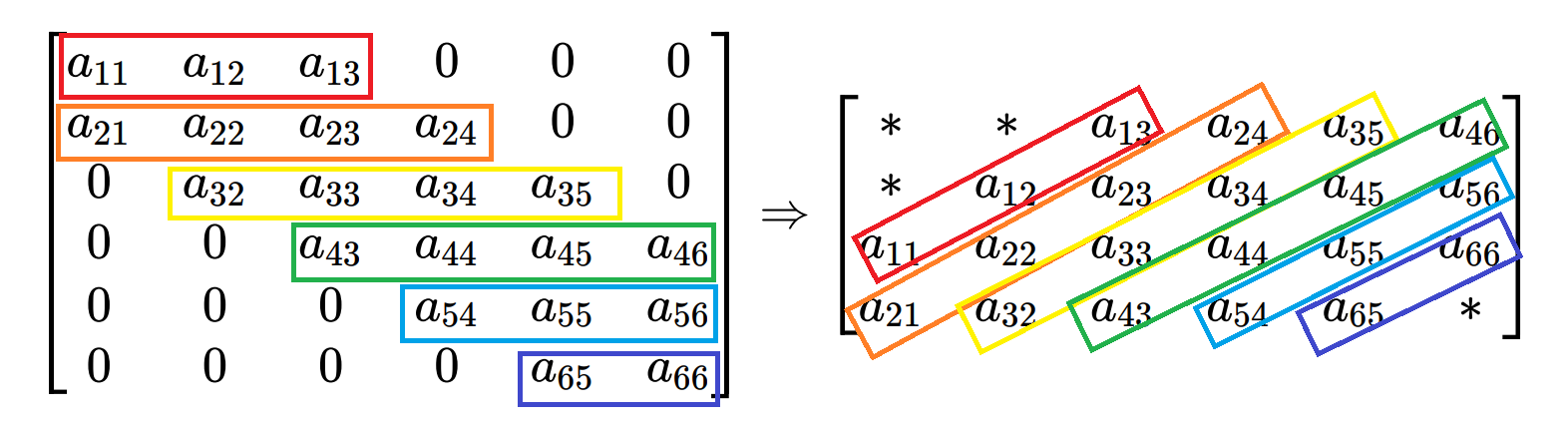
普通 n × n n \times n n × n n 2 n^2 n 2 ( p + q + 1 ) × n (p+q+1) \times n ( p + q + 1 ) × n
a i j ⇒ a ˉ i − j + q + 1 , j a_{ij} \Rightarrow \bar{a}_{i-j+q+1,j} a ij ⇒ a ˉ i − j + q + 1 , j 其中 A ˉ ∈ R ( p + q + 1 ) × n \bar{A} \in \mathbb{R}^{(p+q+1) \times n} A ˉ ∈ R ( p + q + 1 ) × n
图3:下带宽 p=1、上带宽 q=2 的6×6矩阵
数学基础:带状矩阵 LU 分解的稀疏性
若 A = L U A = LU A = LU A A A q q q p p p U U U q q q L L L p p p
注 :并非所有稀疏矩阵的 LU 分解都保持稀疏性(称为”填充”现象),但对于带状矩阵,LU 分解能够保持稀疏性。
未压缩的算法
for k in range (n - 1 ): # 递归的第 k 步,最后一步不用计算 # 红色区域不需计算 for i in range (k + 1 , min (k + p + 1 , n)): # 计算橙色区域 A[i, k] = A[i, k] / A[k, k] for i in range (k + 1 , min (k + p + 1 , n)): # 计算黄色区域 for j in range (k + 1 , min (k + q + 1 , n)): A[i, j] = A[i, j] - A[i, k] * A[k, j] 复杂度分析 :
当 n ≫ p , q n \gg p,q n ≫ p , q n p q npq n pq n p q npq n pq O ( n p q ) O(npq) O ( n pq )
正定矩阵的 Cholesky 分解
数学基础:正定矩阵
定义 :矩阵 A A A A ⊤ = A A^\top = A A ⊤ = A x ∈ R n \mathbf{x} \in \mathbb{R}^n x ∈ R n x ⊤ A x > 0 \mathbf{x}^\top A\mathbf{x} > 0 x ⊤ A x > 0
重要性质 :
A A A A A A A A A A A A A − 1 A^{-1} A − 1 A A A
几何意义 :SPD 矩阵对应的二次型 x ⊤ A x \mathbf{x}^\top A\mathbf{x} x ⊤ A x R n \mathbb{R}^n R n
数学基础:Cholesky 分解的存在唯一性
若 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n L L L
A = L L ⊤ A = LL^\top A = L L ⊤ 证明 :
记 A k A_k A k A A A k k k A A A A k A_k A k n = 1 n=1 n = 1 A = [ a 11 ] A = [a_{11}] A = [ a 11 ] a 11 > 0 a_{11} > 0 a 11 > 0
假设对 n ≤ k − 1 n \le k-1 n ≤ k − 1 A k − 1 A_{k-1} A k − 1 A k − 1 = L k − 1 L k − 1 ⊤ A_{k-1} = L_{k-1} L_{k-1}^\top A k − 1 = L k − 1 L k − 1 ⊤ L k − 1 L_{k-1} L k − 1 n = k n = k n = k
将 A k A_k A k
A k = [ A k − 1 v v ⊤ a k k ] , A_k =
\begin{bmatrix}
A_{k-1} & v \\
v^\top & a_{kk}
\end{bmatrix}, A k = [ A k − 1 v ⊤ v a k k ] , 其中 v ∈ R k − 1 v \in \mathbb{R}^{k-1} v ∈ R k − 1 a k k > 0 a_{kk} > 0 a k k > 0
设待求的 L k L_k L k
L k = [ L k − 1 0 w ⊤ l k k ] , L_k =
\begin{bmatrix}
L_{k-1} & 0 \\
w^\top & l_{kk}
\end{bmatrix}, L k = [ L k − 1 w ⊤ 0 l k k ] , 其中 L k − 1 L_{k-1} L k − 1 w ∈ R k − 1 w \in \mathbb{R}^{k-1} w ∈ R k − 1 l k k > 0 l_{kk} > 0 l k k > 0
计算
L k L k ⊤ = [ L k − 1 0 w ⊤ l k k ] [ L k − 1 ⊤ w 0 l k k ] = [ L k − 1 L k − 1 ⊤ L k − 1 w w ⊤ L k − 1 ⊤ w ⊤ w + l k k 2 ] . L_k L_k^\top =
\begin{bmatrix}
L_{k-1} & 0 \\
w^\top & l_{kk}
\end{bmatrix}
\begin{bmatrix}
L_{k-1}^\top & w \\
0 & l_{kk}
\end{bmatrix}
=
\begin{bmatrix}
L_{k-1} L_{k-1}^\top & L_{k-1} w \\
w^\top L_{k-1}^\top & w^\top w + l_{kk}^2
\end{bmatrix}. L k L k ⊤ = [ L k − 1 w ⊤ 0 l k k ] [ L k − 1 ⊤ 0 w l k k ] = [ L k − 1 L k − 1 ⊤ w ⊤ L k − 1 ⊤ L k − 1 w w ⊤ w + l k k 2 ] . 令其等于 A k A_k A k
{ A k − 1 = L k − 1 L k − 1 ⊤ (由归纳假设已知) v = L k − 1 w (1) a k k = w ⊤ w + l k k 2 (2) (2) \begin{cases}
A_{k-1} = L_{k-1} L_{k-1}^\top & \text{(由归纳假设已知)}\\
v = L_{k-1} w & \text{(1)}\\
a_{kk} = w^\top w + l_{kk}^2 & \text{(2)}
\end{cases}
\tag{2} ⎩ ⎨ ⎧ A k − 1 = L k − 1 L k − 1 ⊤ v = L k − 1 w a k k = w ⊤ w + l k k 2 ( 由归纳假设已知 ) (1) (2) ( 2 ) 则 Cholesky 分解存在且唯一等价于方程组 ( 2 ) (2) ( 2 ) w = L k − 1 − 1 v w = L_{k-1}^{-1} v w = L k − 1 − 1 v a k k − w ⊤ w > 0 a_{kk} - w^\top w > 0 a k k − w ⊤ w > 0
由正定性,对任意非零向量 x ∈ R k x \in \mathbb{R}^k x ∈ R k x ⊤ A k x > 0 x^\top A_k x > 0 x ⊤ A k x > 0 x = ( − L k − 1 − T w 1 ) x = \begin{pmatrix} -L_{k-1}^{-T} w \\ 1 \end{pmatrix} x = ( − L k − 1 − T w 1 ) k − 1 k-1 k − 1
x ⊤ A k x = ( − w ⊤ L k − 1 − 1 1 ) [ A k − 1 v v ⊤ a k k ] ( − L k − 1 − T w 1 ) = ( − w ⊤ L k − 1 − 1 1 ) [ L k − 1 L k − 1 ⊤ L k − 1 w w ⊤ L k − 1 ⊤ a k k ] ( − L k − 1 − T w 1 ) = a k k − w ⊤ w > 0. x^\top A_k x = \begin{pmatrix} -w^\top L_{k-1}^{-1} & 1 \end{pmatrix}
\begin{bmatrix}
A_{k-1} & v \\
v^\top & a_{kk}
\end{bmatrix}
\begin{pmatrix} -L_{k-1}^{-T} w \\ 1 \end{pmatrix} \\
=
\begin{pmatrix} -w^\top L_{k-1}^{-1} & 1 \end{pmatrix}
\begin{bmatrix}
L_{k-1} L_{k-1}^\top & L_{k-1} w \\
w^\top L_{k-1}^\top & a_{kk}
\end{bmatrix}
\begin{pmatrix} -L_{k-1}^{-T} w \\ 1 \end{pmatrix} \\
= a_{kk} - w^\top w > 0. x ⊤ A k x = ( − w ⊤ L k − 1 − 1 1 ) [ A k − 1 v ⊤ v a k k ] ( − L k − 1 − T w 1 ) = ( − w ⊤ L k − 1 − 1 1 ) [ L k − 1 L k − 1 ⊤ w ⊤ L k − 1 ⊤ L k − 1 w a k k ] ( − L k − 1 − T w 1 ) = a k k − w ⊤ w > 0. 于是存在唯一性得证。
Cholesky 分解计算公式
从 A = L L ⊤ A=L L^\top A = L L ⊤
l k k = a k k − ∑ j = 1 k − 1 l k j 2 , k = 1 , 2 , 3 , … , n l_{kk} = \sqrt{a_{kk} - \sum_{j=1}^{k-1} l_{kj}^2}, \quad k=1,2,3,\dots,n l k k = a k k − j = 1 ∑ k − 1 l k j 2 , k = 1 , 2 , 3 , … , n l i k = 1 l k k ( a i k − ∑ j = 1 k − 1 l i j l k j ) , i = k + 1 , k + 2 , … , n l_{ik} = \frac{1}{l_{kk}}\left(a_{ik} - \sum_{j=1}^{k-1} l_{ij}l_{kj}\right), \quad i=k+1,k+2,\dots,n l ik = l k k 1 ( a ik − j = 1 ∑ k − 1 l ij l k j ) , i = k + 1 , k + 2 , … , n 证明 :
矩阵乘法:
a i j = ( L L ⊤ ) i j = ∑ k = 1 n l i k l j k = ∑ k = 1 min ( i , j ) l i k l j k . a_{ij} = (LL^\top)_{ij} = \sum_{k=1}^n l_{ik} l_{jk} = \sum_{k=1}^{\min(i, j)} l_{ik} l_{jk}. a ij = ( L L ⊤ ) ij = k = 1 ∑ n l ik l j k = k = 1 ∑ m i n ( i , j ) l ik l j k . 由于 L L L l i k = 0 l_{ik} = 0 l ik = 0 i < k i < k i < k l j k = 0 l_{jk} = 0 l j k = 0 j < k j < k j < k min ( i , j ) \min(i, j) min ( i , j )
实际操作时应按照下图所示的红橙黄绿顺序依次求解。也即先由上式求出 a 11 a_{11} a 11 a 1 a_1 a 1 a 1 a^1 a 1 a 22 a_{22} a 22
图4:Cholesky 分解求解顺序
Cholesky 分解代码
标准 Cholesky 分解
L = np.zeros(n, n) for k in range (n): # 求解对角元 L[k, k] = A[k, k] for j in range (k): L[k, k] = L[k, k] - L[k, j] * L[k, j] L[k, k] = np.sqrt(L[k, k]) # 求解对角元下侧(右侧)的剩余元 for i in range (k + 1 , n): L[i, k] = A[i, k] for j in range (k): L[i, k] = L[i, k] - L[i, j] * L[k, j] L[i, k] = L[i, k] / L[k, k] 原位存储 Cholesky 分解
对于对称正定矩阵
A = [ a 11 l ⊤ l B ] A = \begin{bmatrix}
a_{11} & \mathbf{l}^\top \\
\mathbf{l} & B
\end{bmatrix} A = [ a 11 l l ⊤ B ] 其中 a 11 > 0 a_{11} > 0 a 11 > 0 B B B
则:
A = [ a 11 0 l / a 11 I n − 1 ] [ 1 0 0 B − l l ⊤ / a 11 ] [ a 11 l ⊤ / a 11 0 I n − 1 ] A = \begin{bmatrix}
\sqrt{a_{11}} & 0 \\
\mathbf{l}/\sqrt{a_{11}} & I_{n-1}
\end{bmatrix}
\begin{bmatrix}
1 & 0 \\
0 & B - \mathbf{l}\mathbf{l}^\top / a_{11}
\end{bmatrix}
\begin{bmatrix}
\sqrt{a_{11}} & \mathbf{l}^\top/\sqrt{a_{11}} \\
0 & I_{n-1}
\end{bmatrix} A = [ a 11 l / a 11 0 I n − 1 ] [ 1 0 0 B − l l ⊤ / a 11 ] [ a 11 0 l ⊤ / a 11 I n − 1 ] 其中 B − l l ⊤ / a 11 B - \mathbf{l}\mathbf{l}^\top/a_{11} B − l l ⊤ / a 11 B − l l ⊤ / a 11 = L n − 1 L n − 1 ⊤ B - \mathbf{l}\mathbf{l}^\top/a_{11} = L_{n-1} L_{n-1}^\top B − l l ⊤ / a 11 = L n − 1 L n − 1 ⊤
A = [ a 11 0 l / a 11 L n − 1 ] [ a 11 l ⊤ / a 11 0 L n − 1 ⊤ ] A = \begin{bmatrix}
\sqrt{a_{11}} & 0 \\
\mathbf{l}/\sqrt{a_{11}} & L_{n-1}
\end{bmatrix}
\begin{bmatrix}
\sqrt{a_{11}} & \mathbf{l}^\top/\sqrt{a_{11}} \\
0 & L_{n-1}^\top
\end{bmatrix} A = [ a 11 l / a 11 0 L n − 1 ] [ a 11 0 l ⊤ / a 11 L n − 1 ⊤ ] 原位存储的 Cholesky 分解 :
实际上每一递归步都是按照红橙黄的顺序进行计算,其中红橙色区域计算得到的是最终值,而黄色区域计算得到的是中间值。又由于对称性,所以我们只使用和计算下三角部分。
for k in range (n): # 计算红色区域 A[k, k] = np.sqrt(A[k, k]) # 计算橙色区域 for i in range (k + 1 , n): A[i, k] = A[i, k] / A[k, k] # 计算黄色区域 for i in range (k + 1 , n): for j in range (i, n): A[i, j] = A[i, j] - A[i, k] * A[j, k] # 前面已经除了,故不需再除
图5:递归 Cholesky 分解求解顺序
注 :利用了对称性,只需计算下三角部分,存储空间和运算量都减半。
LDL^T 分解
当矩阵对称但不一定是正定时,可采用 L D L T LDL^T L D L T n n n
数学基础:LDL^T 分解的存在唯一性
定理 :
设 A ∈ R n × n A \in \mathbb{R}^{n \times n} A ∈ R n × n det ( A k ) ≠ 0 \det(A_k) \neq 0 det ( A k ) = 0 A k A_k A k A A A k k k L L L 1 1 1 D D D d k ≠ 0 d_k \neq 0 d k = 0
A = L D L T A = LDL^T A = L D L T 特别地,若 A A A d k > 0 d_k > 0 d k > 0
与 Cholesky 分解的关系 :A = L L ⊤ A = LL^\top A = L L ⊤ L D L T LDL^T L D L T L chol = L ldl D L_{\text{chol}} = L_{\text{ldl}} \sqrt{D} L chol = L ldl D
证明 :
采用归纳法。
n = 1 n=1 n = 1
假设对 n ≤ k − 1 n \le k-1 n ≤ k − 1 n = k n=k n = k
将 A k A_k A k
A k = [ A k − 1 v v ⊤ a k k ] , A_k =
\begin{bmatrix}
A_{k-1} & v \\
v^\top & a_{kk}
\end{bmatrix}, A k = [ A k − 1 v ⊤ v a k k ] , 其中 v ∈ R k − 1 v \in \mathbb{R}^{k-1} v ∈ R k − 1
由归纳假设,A k − 1 = L k − 1 D k − 1 L k − 1 ⊤ A_{k-1} = L_{k-1} D_{k-1} L_{k-1}^\top A k − 1 = L k − 1 D k − 1 L k − 1 ⊤ L k L_k L k D k D_k D k
L k = [ L k − 1 0 w ⊤ 1 ] , D k = [ D k − 1 0 0 d k k ] , L_k =
\begin{bmatrix}
L_{k-1} & 0 \\
w^\top & 1
\end{bmatrix},
\quad
D_k =
\begin{bmatrix}
D_{k-1} & 0 \\
0 & d_{kk}
\end{bmatrix}, L k = [ L k − 1 w ⊤ 0 1 ] , D k = [ D k − 1 0 0 d k k ] , 其中 w ∈ R k − 1 w \in \mathbb{R}^{k-1} w ∈ R k − 1 d k k ≠ 0 d_{kk} \neq 0 d k k = 0
计算 L k D k L k ⊤ L_k D_k L_k^\top L k D k L k ⊤
L k D k L k ⊤ = [ L k − 1 D k − 1 L k − 1 ⊤ L k − 1 D k − 1 w w ⊤ D k − 1 L k − 1 ⊤ w ⊤ D k − 1 w + d k k ] . L_k D_k L_k^\top =
\begin{bmatrix}
L_{k-1} D_{k-1} L_{k-1}^\top & L_{k-1} D_{k-1} w \\
w^\top D_{k-1} L_{k-1}^\top & w^\top D_{k-1} w + d_{kk}
\end{bmatrix}. L k D k L k ⊤ = [ L k − 1 D k − 1 L k − 1 ⊤ w ⊤ D k − 1 L k − 1 ⊤ L k − 1 D k − 1 w w ⊤ D k − 1 w + d k k ] . 令其等于 A k A_k A k
{ A k − 1 = L k − 1 D k − 1 L k − 1 ⊤ (由归纳假设满足) v = L k − 1 D k − 1 w (1) a k k = w ⊤ D k − 1 w + d k k (2) \begin{cases}
A_{k-1} = L_{k-1} D_{k-1} L_{k-1}^\top & \text{(由归纳假设满足)}\\
v = L_{k-1} D_{k-1} w & \text{(1)}\\
a_{kk} = w^\top D_{k-1} w + d_{kk} & \text{(2)}
\end{cases} ⎩ ⎨ ⎧ A k − 1 = L k − 1 D k − 1 L k − 1 ⊤ v = L k − 1 D k − 1 w a k k = w ⊤ D k − 1 w + d k k ( 由归纳假设满足 ) (1) (2) 由 (1) 解得
w = D k − 1 − 1 L k − 1 − 1 v . w = D_{k-1}^{-1} L_{k-1}^{-1} v. w = D k − 1 − 1 L k − 1 − 1 v . 由于 L k − 1 L_{k-1} L k − 1 D k − 1 D_{k-1} D k − 1 w w w
代入 (2) 得
d k k = a k k − w ⊤ D k − 1 w . d_{kk} = a_{kk} - w^\top D_{k-1} w. d k k = a k k − w ⊤ D k − 1 w . d k k d_{kk} d k k L k L_k L k D k D_k D k
需要验证 d k k ≠ 0 d_{kk} \neq 0 d k k = 0 :由条件 det ( A k ) ≠ 0 \det(A_k) \neq 0 det ( A k ) = 0
det ( A k ) = det ( L k D k L k ⊤ ) = det ( D k ) = ( ∏ i = 1 k − 1 d i ) ⋅ d k k . \det(A_k) = \det(L_k D_k L_k^\top) = \det(D_k) = \left( \prod_{i=1}^{k-1} d_i \right) \cdot d_{kk}. det ( A k ) = det ( L k D k L k ⊤ ) = det ( D k ) = ( i = 1 ∏ k − 1 d i ) ⋅ d k k . 由归纳假设 ∏ i = 1 k − 1 d i = det ( A k − 1 ) ≠ 0 \prod_{i=1}^{k-1} d_i = \det(A_{k-1}) \neq 0 ∏ i = 1 k − 1 d i = det ( A k − 1 ) = 0 det ( A k ) ≠ 0 \det(A_k) \neq 0 det ( A k ) = 0 d k k ≠ 0 d_{kk} \neq 0 d k k = 0
当正定时,显然可知所有 d k > 0 d_k \gt 0 d k > 0
LDL^T 分解计算公式
从 A = L D L T A = LDL^T A = L D L T L L L D = diag ( d 1 , d 2 , … , d n ) D = \operatorname{diag}(d_1, d_2, \dots, d_n) D = diag ( d 1 , d 2 , … , d n )
d k = a k k − ∑ j = 1 k − 1 l k j 2 d j , k = 1 , 2 , … , n d_k = a_{kk} - \sum_{j=1}^{k-1} l_{kj}^2 d_j, \quad k=1,2,\dots,n d k = a k k − j = 1 ∑ k − 1 l k j 2 d j , k = 1 , 2 , … , n l i k = 1 d k ( a i k − ∑ j = 1 k − 1 l i j l k j d j ) , i = k + 1 , … , n l_{ik} = \frac{1}{d_k} \left( a_{ik} - \sum_{j=1}^{k-1} l_{ij} l_{kj} d_j \right), \quad i=k+1,\dots,n l ik = d k 1 ( a ik − j = 1 ∑ k − 1 l ij l k j d j ) , i = k + 1 , … , n 证明 :
由 A = L D L T A = LDL^T A = L D L T L L L 1 1 1
a i j = ∑ k = 1 min ( i , j ) l i k d k l j k . a_{ij} = \sum_{k=1}^{\min(i,j)} l_{ik} d_k l_{jk}. a ij = k = 1 ∑ m i n ( i , j ) l ik d k l j k . 实际操作时计算顺序与 Cholesky 分解类似,不过此处对角元在 D 中计算。
LDL^T 分解代码
标准 LDL^T 分解
L = np.eye(n) D = np.zeros(n) for k in range (n): # 计算 D 中对角元 d_k D[k] = A[k, k] for j in range (k): D[k] = D[k] - L[k, j] * L[k, j] * D[j] # 计算 L 中第 k 列严格下三角部分 for i in range (k + 1 , n): L[i, k] = A[i, k] for j in range (k): L[i, k] = L[i, k] - L[i, j] * L[k, j] * D[j] L[i, k] = L[i, k] / D[k] 原位存储 LDL^T 分解
对于对称阵
A = [ a 11 l ⊤ l B ] A = \begin{bmatrix}
a_{11} & \mathbf{l}^\top \\
\mathbf{l} & B
\end{bmatrix} A = [ a 11 l l ⊤ B ] 其中 a 11 ≠ 0 a_{11} \ne 0 a 11 = 0 B B B
则:
A = [ 1 0 l / a 11 I n − 1 ] [ a 11 0 0 B − l l ⊤ / a 11 ] [ 1 l ⊤ / a 11 0 I n − 1 ] A = \begin{bmatrix}
1 & 0 \\
\mathbf{l}/a_{11} & I_{n-1}
\end{bmatrix}
\begin{bmatrix}
a_{11} & 0 \\
0 & B - \mathbf{l}\mathbf{l}^\top / a_{11}
\end{bmatrix}
\begin{bmatrix}
1 & \mathbf{l}^\top/a_{11} \\
0 & I_{n-1}
\end{bmatrix} A = [ 1 l / a 11 0 I n − 1 ] [ a 11 0 0 B − l l ⊤ / a 11 ] [ 1 0 l ⊤ / a 11 I n − 1 ] 其中 B − l l ⊤ / a 11 B - \mathbf{l}\mathbf{l}^\top / a_{11} B − l l ⊤ / a 11 L D L T LDL^T L D L T B − l l ⊤ / a 11 = L n − 1 D n − 1 L n − 1 ⊤ B - \mathbf{l}\mathbf{l}^\top / a_{11} = L_{n-1}D_{n-1}L_{n-1}^\top B − l l ⊤ / a 11 = L n − 1 D n − 1 L n − 1 ⊤
A = [ 1 0 l / a 11 L n − 1 ] [ a 11 0 0 D n − 1 ] [ 1 l ⊤ / a 11 0 L n − 1 ⊤ ] A = \begin{bmatrix}
1 & 0 \\
\mathbf{l}/a_{11} & L_{n-1}
\end{bmatrix}
\begin{bmatrix}
a_{11} & 0 \\
0 & D_{n-1}
\end{bmatrix}
\begin{bmatrix}
1 & \mathbf{l}^\top/a_{11} \\
0 & L_{n-1}^\top
\end{bmatrix} A = [ 1 l / a 11 0 L n − 1 ] [ a 11 0 0 D n − 1 ] [ 1 0 l ⊤ / a 11 L n − 1 ⊤ ] 原位存储时,我们只需存储下三角部分(包括对角元),最终 A A A L L L D D D
for k in range (n): # 计算 D 中对角元 d_k,暂存在 A[k, k] for i in range (k + 1 , n): A[i, k] = A[i, k] / A[k, k] # 计算 L 中第 k 列严格下三角部分 for i in range (k + 1 , n): for j in range (i, n): A[i, j] = A[i, j] - A[i, k] * A[j, k] # 前面已经除了,故不需再除 注 :L D L T LDL^T L D L T D D D
方法对比与总结
各种分解方法对比
方法 适用条件 存储需求 运算量 特点 LU 分解 一般方阵(顺序主子式非零) n 2 n^2 n 2 2 3 n 3 \frac{2}{3}n^3 3 2 n 3 通用性强,适合多次右端项求解 Cholesky 分解 对称正定矩阵 1 2 n 2 \frac{1}{2}n^2 2 1 n 2 1 3 n 3 \frac{1}{3}n^3 3 1 n 3 运算量少,数值稳定性好 LDL^T 分解 对称矩阵(顺序主子式非零) 1 2 n 2 \frac{1}{2}n^2 2 1 n 2 1 3 n 3 \frac{1}{3}n^3 3 1 n 3 无需开方,适用于对称不定矩阵 带状 LU 分解 带状矩阵 ( p + q + 1 ) n (p+q+1)n ( p + q + 1 ) n n p q npq n pq 利用稀疏性,效率高
数值稳定性对比
LU 分解 :若主元很小,可能导致舍入误差放大,需列主元(PLU分解)提高稳定性。Cholesky 分解 :若主元 l k k = a k k ( k ) l_{kk} = \sqrt{a_{kk}^{(k)}} l k k = a k k ( k ) LDL^T 分解 :对称矩阵中,若 D D D